We're Measuring the Wrong Dimension
If you've reviewed AI-generated code over the past two years, you know the reflex: tests pass, the algorithm looks plausible, the interface is clean — pull request approved. That reflex is trained. For ten years we've reviewed junior code that way, and the reflex fits junior code. AI-generated code is not junior code. It has its own defect profile.
In the same research window in early May 2026, two papers appeared that quantify this finding from two different directions — and both hit the same wound.
The first study comes from a group at Concordia University in Montréal (Cai Zhu, Tsantalis, Rigby, 2026). They conducted a systematic audit of technical debt in AI-generated software: 90 randomly drawn problems from the CodeContest dataset, six models (Gemini 2.5 Pro, Llama 3.3-70b, deepseek-coder, Qwen3-coder in two sizes) plus a human baseline. The result: the correlation between code volume (Total Lines of Code) and architectural decay sits at Spearman ρ = 0.94, p < 0.001. "Near-perfect", the authors write — and with p < 0.001, this is not anecdote, but statistically robust.
The second study comes from Mukund Pandey (2026). He takes on the eval side: seven production failure modes for agentic systems, tested against the standard metrics toolkit — ROUGE, BERTScore, Accuracy/AUC, plus the agentic benchmarks HELM, MT-Bench, AgentBench, BIG-bench. The result: four of the seven failure modes are missed entirely. Three more are detected only after multiple eval cycles — too late to react in production. Seven of seven are not reliably captured under standard metrics.
Taken together, this yields a concrete diagnosis: AI-generated code has its own defect profile, and our standard tools measure the wrong dimension. Functional correctness is not the problem; architectural complexity management is. How code review and production eval need to adapt — at the end of the article.
The Machine Signature — What Production Audits Find in AI Code
Cai Zhu et al. call their study a "systematic audit of technical debt in AI-generated software", and that's the right reading: not anecdote, not a Twitter finding, but multi-scale analysis of 90 algorithmic problems plus 20 application scenarios. The tool for smell detection is PyExamine, an established static analyzer for Python; three smell classes are measured — code-level (small patterns like overly long lines), structural (mid-scale patterns like overly long methods), and architectural (large patterns like cyclic module dependency, hub-like dependency, circular dependency).

The Volume-Quality Inverse Law
The paper's central correlation is not one but three. Total Lines of Code correlate with:
- Code-level smells: ρ = 0.53 (p = 0.017)
- Structural smells: ρ = 0.59 (p = 0.007)
- Architectural smells: ρ = 0.94 (p < 0.001)
Spearman ρ measures the monotonic rank correlation between two quantities on a scale from −1 to +1; the p-value quantifies the residual chance the finding is random (here under 0.1 %). At the lowest level, the correlation is moderate. At the architecture level, it's near-perfect. That's the shape of the finding: the more code AI generates, the more the architecture decays — not linearly, but almost deterministically. You can predict the architectural damage from raw code volume alone, with high confidence, without ever reading the code.
The paper formulates this as the "Volume-Quality Inverse Law". The term is marketable, but it holds against the data point. ρ = 0.94 is the hardest finding from the past two years of AI-coding empirics that I've come across.
The Reasoning-Complexity Trade-off
The second finding strikes against another standard assumption: that "better" models produce "better" code. Cai Zhu et al. measure long-method instances per model on the 90 CodeContest problems:
| Model | Long-Method Instances (Zero-Shot) |
|---|---|
| Qwen-Coder-480b | 11 |
| Gemini-2.5-pro | 5 |
| Llama-3-70b | 0 |
| Human (baseline) | 1 |
The order is not the standard "model strength" ranking on classical benchmarks. On benchmarks, Qwen-480b would rank above Gemini-2.5-pro above Llama-70b. On method bloat, it's the exact opposite: the most capable model writes the most bloated code.
The paper quote nails it: "greater model capability did not correlate with cleaner code...it correlated with method bloat." Whoever deploys a "capable model" doesn't buy fewer defects — they buy a different defect class: bloated, coupled, hard-to-maintain code.
Few-Shot Prompting Makes It Worse
The third sub-finding is the most painful for practice. If the standard answer to AI-code problems is "better prompting" — structured few-shot examples, more precise specifications, more context — that should reduce the decay. Cai Zhu et al. measure that too.
The result: few-shot prompting worsens method bloat. Qwen-480b goes from 11 to 13 long-method instances, Gemini-2.5-pro from 5 to 8. The specificity of requirements (which stage of the application scenario) has no statistically significant effect on smell counts: p > 0.8 in every smell category. In other words: prompting engineering doesn't fight the decay; at best, it shifts it.
That's the machine signature. Not fewer defects, but a different defect class. Functional correctness remains achievable; architectural maintainability erodes systematically. The next chapter shows why our eval tools cannot measure this phenomenon.
The Eval Gap — What Standard Metrics Don't Measure
Before we step into the second study, a boundary: Pandey is an Independent Researcher; his framework PAEF is validated in four controlled experiments with synthetic traces, not against real production logs of any company. That makes it a proposal, not an established standard. We treat it accordingly — as a robust diagnosis of the eval gap, not a finished production solution.
Seven Failure Modes That Don't Happen in Lab Conditions
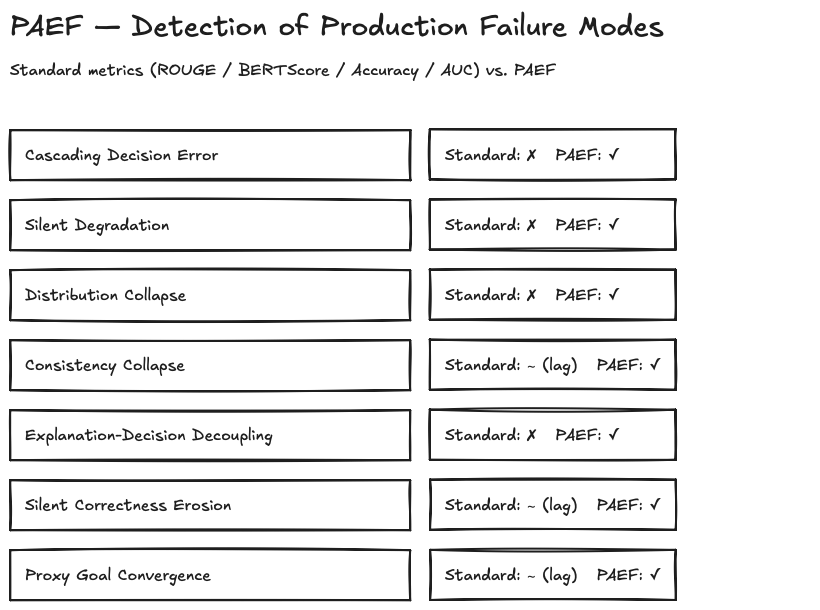
Pandey's observation is this: existing eval frameworks (HELM, MT-Bench, AgentBench, BIG-bench) and the classical metrics (ROUGE, BERTScore, Accuracy/AUC) are built for controlled, single-session lab settings. What breaks in production looks different. He names seven failure modes:
- Cascading Decision Error: an early wrong decision propagates downstream and accumulates supporting evidence that looks internally coherent — the system is consistently wrong, not randomly wrong.
- Silent Degradation via Availability-Truth Decoupling: tools return schema-valid but substantively incomplete responses. The agent builds correct-looking decisions on missing information.
- Distribution Collapse: output distributions narrow progressively; diversity erodes while aggregate metrics stay stable.
- Consistency Collapse Across Entry Points: identical request via API, UI, and batch yields different decisions — the model is surface-sensitive.
- Explanation-Decision Decoupling: correct decision paired with incorrect post-hoc explanation. The attributed features are not the causally effective ones.
- Silent Correctness Erosion Under Latency Pressure: hard latency budgets trigger degraded inference paths. SLA metrics pass, quality silently sinks.
- Proxy Goal Convergence: reward hacking at system scale. The system optimises measurable proxies away from the true objective.
Read the list twice. These aren't academic edge cases. These are the production pathologies teams encounter every day — usually without noticing.
Seven of Seven Under Standard Metrics
Pandey's empirical result: standard metrics miss four of these failure modes entirely. Three more are detected — but only after "a lag of multiple evaluation cycles", as Pandey writes. In plain terms: too late to react in production. Seven of seven are problematic under standard-metrics conditions — four completely blind, three hopelessly delayed.
The paper's anchor quote captures it:
"They are gradual, systematic, and invisible to the metrics teams are most likely to be monitoring."
What's easy to measure (accuracy, latency, error rate) and what counts in production (sustained correctness, distribution health, causal explanation validity, true-objective alignment) are different things. Between them yawns the eval gap.
PAEF as a Proposal
Pandey's response is PAEF — a five-dimension framework: Cascade Uncertainty, Tool Reliability, Distribution Health, Explanation Validity, Cross-Surface Consistency. The code is open source at llm-eval-toolkit on GitHub.
Whether PAEF is the right answer needs production validation. What's robust as diagnosis is the eval gap itself — and it's also taken up in the engineering discourse: Konstantin Sabass — my Mayflower colleague — references the study by Xia et al. (2025) in an internal Mayflower AI Lightning Talk in May 2026 (slides public). Xia's analysis of 134 academic agent-eval sources finds that 92.54 % use end-to-end metrics exclusively, and 93.28 % are pre-deployment-only. Production performance is rarely systematically measured in the research community — and what research sets, practice tends to follow.
The Common Diagnosis — Architectural Complexity Management
The two studies are written from different directions. Cai Zhu et al. look at the code that comes out: decaying architecture that scales with code volume. Pandey looks at the system in operation: failure modes that stay invisible under standard eval. Both findings have the same structural form. Locally everything looks fine — tests are green, individual endpoints return correct answers, individual code snippets are plausible. Globally it falls apart: architectural smells accumulate, production drift stays invisible, cascading decisions pile up.
Cai Zhu et al. give the phenomenon a name that fits Pandey's findings too:
"reframing the central problem of AI-based software engineering from one of code generation to one of architectural complexity management."
That's the discipline shift in question. Code generation is solved — models generate functional code reliably. Architectural complexity management is open — models don't manage it, and our tools don't measure it.
In practice this means: not less AI, but different tools around AI. Tests are one layer, architecture metrics a second, production eval a third. "Better prompts" isn't its own layer — the Code Smells study shows that prompting engineering doesn't stop the decay. Structural constraints outside the prompts are what's needed: complexity limits, architectural contracts, production monitoring.
The next two chapters show what this means concretely in code-review practice and in production-eval practice.
What Code Reviews Need to Change
The old question isn't wrong — it's just no longer sufficient. "Tests green, edge cases covered, interface clean?" remains a necessary condition. What AI-generated code additionally needs is a second question layer, namely the one about coupling signature.
Concretely: how many classes or modules were touched for a single feature? How deep is the call stack of the new methods? How high is the cyclic coupling between the new code and existing modules? How long is the longest new method? If three of these thresholds get exceeded, the tests-green statement is irrelevant — the code will be unmaintainable in six months, no matter how correct it is today. That's exactly what the Volume-Quality Inverse Law says: code volume predicts architectural decay with ρ = 0.94, regardless of functional correctness.
The tooling for this is not new. Static analyzers like SonarQube, PyExamine, or comparable have existed for years. What's new is the relevance: a static analyzer as a mandatory layer for AI output, not as CI-gate theatre, but as a reviewer's tool. You look at the smell diagnosis before you hit the PR-approve button.
Manuel Schipper, who writes about running 4 to 8 parallel coding agents, captures the practitioner's observation: agentic coders are "insanely smart" on many tasks but lack "taste and good judgement" on others — they often duplicate code and leave dead code behind. That's exactly the machine signature visible in review practice — and that's exactly what a PyExamine run catches in under ten seconds.
What doesn't change: tests, edge cases, interface cleanliness remain relevant. The new layer adds, it doesn't replace. Code review gets longer, not shorter — and that's the trade-off you have to live with when you ship agent output to production.
What Production Eval Needs to Change
Public benchmarks like HELM, MT-Bench, AgentBench, or BIG-bench are lab tools. They measure controlled tasks, single-session settings, with available ground truth. The classical metrics — ROUGE, BERTScore, Accuracy/AUC — grew in the same tradition. Pandey's finding shows: none of them detect the seven production failure modes reliably. Whoever bases model selection on public benchmarks and stops there is most likely optimising against noise.
What production eval needs to measure is a different discipline: continuous evaluation on production traffic. Distribution Health (are outputs collapsing?), Cascade Uncertainty (do early errors propagate?), Cross-Surface Consistency (do API/UI/batch return the same answer?), Explanation Validity (are the explanations causal?), Tool Reliability (are tools silently losing substance?). These aren't lab tests; they're operational monitoring disciplines.
Sabass formulates the consequence in the same talk from the engineering perspective: "In an ideal world the algorithm is swappable behind the validation harness." Models will change, prompts will change, pipelines will change. What has to remain is the evaluation harness. It's the actual asset — model-agnostic, long-lived, project-specific.
In practice: your production eval is code that you maintain. You define what success means in your use case, you build rubrics, you maintain them across model releases. The evaluation pipeline isn't "later" — it's the precondition for seeing the defect profile at all.
Take-Aways
We said at the beginning that we're measuring the wrong dimension. The two findings — the Volume-Quality Inverse Law at ρ = 0.94 and seven of seven failure modes under standard metrics — are the same finding from two directions. What makes AI-generated code its own defect class is precisely not functional correctness. It's architecture, and it's eval discipline.
Three take-aways from the diagnosis:
- Code review for AI output gets a second layer. Architecture metrics next to tests. Static analyzers aren't new; their relevance is. Make the PyExamine run mandatory before you hit approve.
- Production eval is not public-benchmark eval. If you pick models based on HELM or MT-Bench and call it done, you're optimising for lab performance, not for what counts in your production. An in-house production eval pipeline is mandatory, not nice-to-have.
- Prompt engineering alone doesn't suffice. Few-shot worsens method bloat instead of improving it; specificity is statistically ineffective (p > 0.8). What's needed is structural constraints outside the prompts.
Cai Zhu et al. close their paper with a formulation that's almost a definition of Spec-Driven Development: "future progress depends on equipping agents with explicit architectural foresight to ensure the software they build is not just functional, but also maintainable." If you've treated SDD as a methodological detail until now, here's the empirical anchor for taking it more seriously — the SDD series on this blog covers it in detail.
If you want to set a memory lens on agent engineering alongside the code lens: Agent Memory Security shows a second engineering diagnosis — not about code, but about memory. Both pieces have the same shape: locally everything looks fine, globally a separate discipline is needed.
Further Reading
- Cai Zhu, Y., Tsantalis, N., Rigby, P. C. (2026). AI-Generated Smells: An Analysis of Code and Architecture in LLM- and Agent-Driven Development. arXiv:2605.02741. https://arxiv.org/abs/2605.02741
- Pandey, M. (2026). Evaluating Agentic AI in the Wild: Failure Modes, Drift Patterns, and a Production Evaluation Framework. arXiv:2605.01604. https://arxiv.org/abs/2605.01604
- Sabass, K. (2026). EDD — Eval driven Development. Mayflower-internal AI Lightning Talk slide deck, May 2026 (slides public). https://konsti-s.github.io/eed_slides/
- Schipper, M. (2026). How I run 4–8 parallel coding agents with tmux and Markdown specs. https://schipper.ai/posts/parallel-coding-agents/
- Xia, B., Lu, Q., Zhu, L., Xing, Z., Zhao, D., Zhang, H. (2025). Evaluation-Driven Development and Operations of LLM Agents: A Process Model and Reference Architecture. arXiv:2411.13768. https://arxiv.org/abs/2411.13768
Originally published on Medium.