I had 5 DDD documents. An API documentation, a domain model, an operations manual, a project description, and a technical architecture document. Together they formed the foundation for a desktop app project I'd built in 2025 for an organization: Entity Management, Resource Management, Transaction Tracking. 21 commits in the DDD era, carefully structured with Bounded Contexts and Ubiquitous Language. I'd refined the domain model through 20 iterations, from v1 to v20.
Then the project went dormant. A full year. The stakeholder had other priorities, and those 5 documents sat untouched in a Git repository. Until January 2026.
When I picked it back up, the world had changed. Claude Code, GitHub Copilot, and Cursor had moved AI-assisted development from experiment to everyday reality. And I was facing a question I hadn't planned for: What do I do with my 5 DDD documents in this new world? Throw them out and start over? Or build on them?
This wasn't a typical SDD journey. Nobody converts existing DDD documentation into a new development approach. But that's exactly what happened — and the experience shows why structured specs are indispensable in the AI era.
The Problem: Vibe Coding vs. Structure
"Generate me an entity management system with roles and permissions." 30 seconds, 500 lines of code. It works. Mostly. But why did the agent choose this exact architecture? Which edge cases are missing? And why SQLite instead of PostgreSQL? Ask the agent — it doesn't know, because it never made a deliberate decision.
Welcome to the paradox of AI-assisted development. GitHub Copilot, Claude Code, and Cursor make code generation trivial. One prompt, a few seconds, working code. But our projects don't automatically get better. What happens when you work this way has a name: Vibe Coding. Code without a plan. Prompts without context. Architecture by accident.
The problems are real and recurring. Non-deterministic behavior means the same prompt produces different code. Today you get a clean repository layer, tomorrow a God Object. Run the same prompt twice and you get two different architectures. That's not a bug — it's the nature of Large Language Models. But it turns "just start prompting" into a gamble.
Context loss in longer sessions makes it worse. The agent forgets your early architecture decisions by the third feature. Feature A uses a repository pattern, Feature B bypasses the database layer entirely, Feature C invents its own error handling. Each feature works in isolation — but together, there's no coherent system.
And architecture decisions emerge accidentally instead of deliberately — REST or GraphQL, SQLite or PostgreSQL, monolith or microservices. The agent makes these decisions for you, based on what's statistically most common in its training data. Not based on your project's requirements, not based on your organization's constraints, not based on your users' expectations.
The core problem runs deeper: code generation isn't the bottleneck. Every AI tool can write code faster than you can think. The real bottleneck is understanding, deciding, and structuring. Which features does the user need? How do they connect? Which constraints apply? Which architecture holds up long-term? Who understands the generated code three months from now? No prompt answers these questions on its own.
Spec-Driven Development flips the process: think first, then generate. Define what should be built first, then let the AI write the code. That sounds obvious. But in practice it isn't — because the speed of code generation tempts you to skip the thinking.
What Is SDD?
Spec-Driven Development — SDD for short — is a development approach where well-designed software requirement specifications serve as prompts for AI coding agents. The core idea: specifications become executable. They don't just describe what should be built — they become the direct foundation for working implementations. The spec is the prompt — only structured, complete, and deliberately formulated.
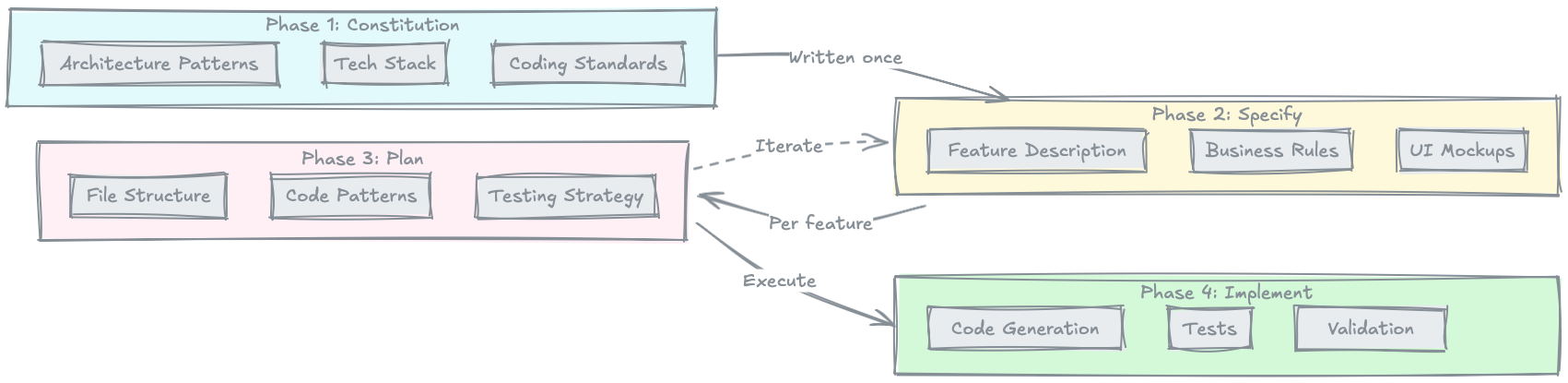
SDD follows four phases:
1. Constitution — The Project Foundation
The Constitution is written once per project and defines the fundamentals: architecture patterns, tech stack, design principles, and coding standards. It's the rulebook that all subsequent decisions reference. Think of it like a country's constitution — it rarely changes, but everything else derives from it.
In my desktop app project, the DDD Constitution became the foundation of the SDD Constitution. The three Bounded Contexts — System/IAM, Entity Management, and Resource Management — defined the architecture. The Ubiquitous Language from the domain model became the terminology in the specs.
2. Specify — WHAT Gets Built
Per feature, you describe what should be built: business rules, UI mockups, scenarios. Deliberately without technical implementation details. Not a word about database schemas or API endpoints. Just pure business logic in the language of the domain.
Why this separation? Because technical details in the Specify phase push the AI in a specific direction before the business requirements are fully understood. If you mention "PostgreSQL" in the spec, the agent will orient its entire implementation around it — even if SQLite would be better suited for your use case.
3. Plan — HOW It Gets Implemented
Now comes the technical strategy: Which files get created? Which patterns are used? What does the file structure look like? Which mapping tables connect business concepts to technical structures? The Plan references the Constitution for overarching decisions and the Spec for business requirements — but it contains no code. It describes the strategy, not the implementation.
4. Implement — Code Generation by AI
Only now does code get written. The AI agent works on the basis of Constitution, Specs, and Plans. It has the full context: what the project is (Constitution), what should be built (Specify), and how it's technically implemented (Plan). That's the crucial difference to Vibe Coding: the agent doesn't generate into the void, but on a documented, deliberately established foundation.
Comparison to Waterfall
SDD often gets reflexively compared to Waterfall. "That's just Big Design Upfront!" This objection falls short. The differences are fundamental:
| Aspect | Waterfall | SDD |
|---|---|---|
| Feedback Loop | Long (months) | Short (hours/days) |
| Flexibility | Rigid (Big Design Upfront) | Iterative (feature-by-feature) |
| AI Integration | None | Central |
| Risk | Late failure | Early validation |
| Documentation | Often outdated | Living Documentation |
The crucial difference: SDD is iterative. You specify a feature in a few hours, implement it, validate the result, and move on to the next feature. Constitution is written once. Specify and Plan run per feature. Feedback comes early and often — not after months.
Comparison to TDD
Test-Driven Development also gets brought up as a comparison. Both approaches emphasize "think first, implement second," but at different levels. TDD defines how code gets tested — at the code level, with concrete assertions for individual functions. SDD defines what gets built — at the feature level, with business rules and scenarios. The two approaches aren't mutually exclusive — they complement each other: SDD provides the foundation for which tests should be written, and TDD ensures the implementation is correct.
External Standards
I didn't learn SDD from a textbook. My workflow emerged organically, from working with DDD documents and AI agents. Only when I read the external standards did I realize my workflow already was SDD. These standards validated my approach — and showed me that others had independently reached the same conclusions.
GitHub Spec-Kit
GitHub released Spec-Kit, an open-source CLI tool that makes SDD actionable. It's technology-agnostic, works with more than 16 AI agents — from Claude Code to GitHub Copilot to Cursor — and structures the development process with 5 core commands: constitution, specify, plan, tasks, and implement. Spec-Kit isn't a code generator — it's a process framework with guardrails and organizational principles. The key thing: it doesn't force you into a specific tech stack or architecture. It only structures the process — the order in which you think about your project.
Thoughtworks SDD Article
In December 2024, Thoughtworks published "Spec-Driven Development: Unpacking 2025 New Engineering Practices". It defines 5 core principles that form the conceptual framework for SDD:
- Shorter feedback loops — Hours and days instead of months. Specify a feature, implement it, validate, repeat.
- Structured requirements analysis — Against "Vibe Coding." Formalized specs instead of vague prompts.
- Domain-oriented language — Specs in the language of the business, not in tech jargon.
- Completeness with brevity — Capture the critical path, not every conceivable edge case. As much as necessary, as little as possible.
- Separation of business and tech — Deliberately separate WHAT gets built (Specify) from HOW it gets implemented (Plan).
Thoughtworks is honest that SDD is still experimental. Evaluation methods for "good specs" are still missing. The question of whether specs or code are the primary artifact isn't definitively answered. But the direction is right.
Addy Osmani
Addy Osmani describes a related approach in his AI coding workflow from the perspective of a Google engineer. He emphasizes structured prompts and iterative refinement — no blind "generate me code," but a deliberate process with clear context and explicit constraints. His workflow adds the practical dimension to SDD: How do you work effectively with AI agents once the specs are in place? How do you iterate when the first result doesn't fit?
All three sources — GitHub, Thoughtworks, and Osmani — independently reached the same conclusion: structured specifications are the key to maintainable AI-generated code. That's not coincidence — it's convergence showing that the industry has recognized a real problem.
DDD as Foundation for SDD
My path to SDD was unusual because I already had a domain model before SDD entered the picture. The 5 DDD documents — carefully built over a year — became the foundation of the SDD Constitution. This wasn't a deliberate decision — it emerged from the nature of the documents. They already contained everything a Constitution needs: architecture boundaries, a shared language, and an understanding of the domain.
Bounded Contexts became the Constitution structure. My three Bounded Contexts — System/IAM, Entity Management, and Resource Management — directly defined the Constitution's outline. Each context got its own section with its own architecture decisions, its own permissions, and its own data models. The boundaries between contexts were already drawn. SDD just had to adopt them.
Ubiquitous Language became the spec terminology. The domain vocabulary from the domain model flowed directly into the feature specs. When the domain model said "Entities," the specs used "Entities" — not "objects," not "records," not "items." No translation, no interpretation. The language was already defined, consistent, and understood by all stakeholders. That's exactly what Thoughtworks means by "domain-oriented language" — except I hadn't developed it for SDD, but brought it from DDD.
The domain model revealed feature relationships. The v1-to-v20 iterations of the domain model had shown me over months how features naturally connect. Which entities depend on each other. Which operations need to be transactional. Which validations are business-critical. This knowledge flowed into the Specify phase — not as abstract knowledge, but as concrete business rules and scenarios.
The bottom line: DDD provides the WHAT of business. SDD structures the HOW for AI. DDD defines the domain, the language, the boundaries. SDD takes that knowledge and makes it consumable for AI agents — in Constitutions, Specs, and Plans. The two approaches complement each other because they operate at different levels: DDD is a design approach for the domain, SDD is a workflow approach for AI-assisted development.
That's the unusual part of my SDD journey: I already had a well-thought-out domain model, refined through 20 iterations. That significantly accelerated my entry into SDD. The Constitution didn't need to be built from scratch. The domain language didn't need to be defined first. The feature boundaries were already clear.
Anyone starting without DDD groundwork will need to catch up on these steps during the Constitution phase. That doesn't mean you need to learn DDD first to use SDD. But it does mean the Constitution phase should be thorough: define your domain, your language, your architecture boundaries. That initial effort pays off with every subsequent feature — because every spec and every plan builds on that foundation.
Conclusion and Outlook
Spec-Driven Development isn't a silver bullet. It doesn't solve all problems of AI-assisted development. Non-deterministic code generation remains a challenge. Specs can go stale if you don't consciously synchronize them. Evaluation methods for "good specs" are still in their early days.
But SDD is a structured counterpoint to "Vibe Coding." Instead of throwing vague prompts at AI tools and hoping for the best, you deliberately define what should be built before letting the AI work. You separate business requirements from technical implementation. You create living documentation that doesn't go stale after the first sprint. And you give the AI agent the context it needs to generate consistent, architecture-conformant code.
The external standards — GitHub Spec-Kit, Thoughtworks, and Addy Osmani — show that the industry is independently converging on the same principles. That's not coincidence. The AI era needs structured specs because the alternative — unplanned code generation at scale — leads to exactly the problems known from the pre-AI era: tech debt, inconsistent architecture, unmaintainable code. Only faster.
SDD isn't perfect. It requires discipline to keep specs up to date. It requires the willingness to invest time in documentation before code exists. But it's a step in the right direction — away from reactive prompting, toward deliberate design.
The 5 DDD documents were the beginning. What came of them surprised even me.
In the next part, I'll show how I organically discovered SDD — in 153 commits and 10 days. Not from a textbook, but through learning-by-doing with Claude Code as my only tool. From chaotic documentation to a consistent system that actually works. I'll show the mistakes, the refactorings, and the aha moments — unfiltered.
And in Part 3: Why 651 commits later there's still not a single line of production code — and why that's exactly right. Spoiler: "Done" is a myth when quality is the goal.
Further Reading
- Part 2 of this series: SDD in Practice: Learnings from 153 Commits — The practical implementation
- Part 3 of this series: 651 Commits, Zero Lines of Code — Why "Done" Is a Myth — From 153 to 651 commits
- Claude Code Must-Haves: Claude Code Must-Haves — January 2026 — My curated setup for productive work
- Superpowers Skills: github.com/svens-uk/superpowers — Custom skills for structured AI workflows
- GitHub Spec-Kit Repository: github.com/github/spec-kit — The open-source toolkit for SDD
- Thoughtworks SDD Article: Spec-Driven Development: Unpacking 2025 New Engineering Practices — The conceptual foundations
- Addy Osmani AI Coding Workflow: addyosmani.com/blog/ai-coding-workflow — Related workflow approach
This is Part 1 of the SDD series. Part 2 shows the practical implementation: SDD in Practice: Learnings from 153 Commits. Part 3 covers the maturity phase: 651 Commits, Zero Lines of Code — Why "Done" Is a Myth.
This article was originally published on Medium.