
153 commits, 102 specs, consistency 9.9/10. That's how Part 2 of this series ended, late January 2026. I had templates, patterns, a clear three-phase structure — Constitution, Specify, Plan. One commit even declared "Complete Documentation Harmonization (Consistency 10.0/10)." Template compliance 100%, no broken links, no legacy naming issues. Done?
Then 477 more commits came.
Not a planned phase. No "now comes the big polishing." Just the realization that "almost done" with 121 feature specs doesn't mean "a few more tweaks" — it means dozens of decisions I hadn't made yet. Architecture changes that ripped everything open. Validation approaches that didn't scale. Code in specs that had no business being there.
Today the desktop app project stands at 651 commits, 233 Markdown files, 121 feature specs, 14 constitution documents, 84 plans — and exactly zero lines of production code. But I now know what "done" really means.
This is Part 3 of the SDD series. Part 1 explained the theory: why AI agents need structured specifications. Part 2 showed the practice: 153 commits in 10 days, the organic discovery of SDD. This article is about maturity — and why those last 477 commits mattered more than the first 153.
Language-Agnostic Specs: No Code in Phases 2 and 3
Strict phase separation was the most painful lesson of the entire 477 commits. And it started with an insight that seems obvious in hindsight — but took months to truly sink in. It's easy to state phase separation as a principle. It's hard to enforce it in a living project when the pressure to finally start implementing keeps growing.
In Part 2, I described the Reference-Style Pattern: function signatures plus metadata tables instead of full implementations in feature specs. Entity management shrunk from 2,361 to 818 lines — minus 65 percent. I celebrated that as a breakthrough at the time — a drastic reduction that made the specs more readable and maintainable. And it was a good first step — but not far enough.
Because the Plan phase still contained full Rust code blocks. Hundreds of lines of fn, impl, match statements. Every single backend plan read like a half-finished implementation. And that was exactly the problem: as soon as the architecture changed — new table names, different data structures, consolidated status values — those code blocks were instantly outdated. Not slightly outdated. Completely wrong. Because concrete code encodes concrete assumptions that break with every architecture change.
The real insight was more radical than expected: even TypeScript interfaces are implementation code. The moment you pick a syntax — whether Rust, TypeScript, or Python — you're binding the spec to a concrete technology. Phase 2 (Specify) describes WHAT the system should do, not HOW it should do it. And Phase 3 (Plan) describes the strategy of implementation, not the code itself. Code belongs exclusively in Phase 4.
The consequence was painful but necessary: 17 backend implementation plans had to be migrated to mapping tables. Piece by piece, plan by plan. 7,428 lines of code were removed from 33 files. In the end, not a single Rust code block remained in the Plan phase. It felt like a loss at first — all those carefully written code examples, simply deleted. But it was the opposite: it was a liberation. The plans became shorter, clearer, and — crucially — resilient to architecture changes.
What replaced the code? Structured tables. Error handling strategies as mapping tables: which error class, which treatment, which user feedback. Data structures as field tables: name, type, validation, source. Commands as mappings: function, permission, validation rule, pattern reference. Service-to-repository mappings: which service uses which repository for which operation.
That sounds like less information. But it isn't. Claude Code can implement from a mapping table just as reliably as from a full code block — as long as the table has the right dimensions: function, permission, validation, pattern reference. The difference: the mapping table survives architecture changes. A Rust code block doesn't.
At the same time, I introduced a criticality system with four categories. Not every spec needs equally detailed plans. Standard CRUD operations need minimal planning — the pattern is known, the implementation predictable. Complex synchronization logic, on the other hand, needs detailed mapping tables with edge cases and error scenarios. Four levels, from "pattern is enough" to "full strategy documentation." This saves work where work adds no value.
| Before | After |
|---|---|
| Full Rust code in plans | Mapping tables + pattern reference |
| ~400 lines per plan spec | ~120 lines per plan spec |
| Code and spec mixed | Clear phase separation |
| 7,428 lines of code in plans | 0 code blocks in plans |
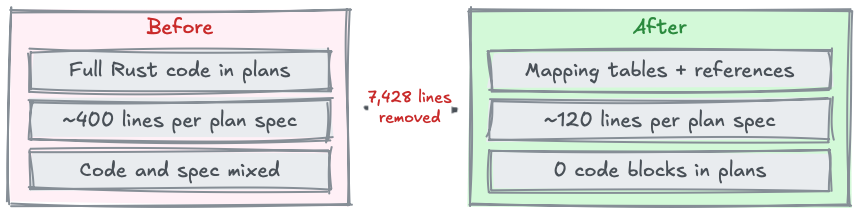
Why does this work? Because an AI agent doesn't need a prescribed implementation — it needs constraints. "This function requires permission X, validates with rule Y, and uses pattern Z" is everything Claude Code needs to implement the function. The agent knows the patterns (they're in the Constitution), it knows the architecture, it knows the validation rules. What it doesn't need is a prescribed code block that'll be obsolete after the next schema change.
The key takeaway from this phase: specs describe WHAT, not HOW. Plans describe strategy, not code. Code belongs in Phase 4 — and only there.
Hybrid Validation: Why LLMs Can't Check Everything
At some point in February, I asked Claude Code: "Check the consistency of the specs." Claude responded confidently, found a few issues, reported the rest as clean. I was satisfied — until I manually opened a file Claude had supposedly checked. The exact same problem that Claude had found in a different file existed here, unnoticed. Claude had sampled — 10 to 20 of 121 files, not all of them.
That's not a bug. It's a fundamental behavioral pattern of LLMs that I call the "Exhaustive Enumeration Problem": LLMs cannot reliably find ALL instances of a problem in a large dataset. They work probabilistically, not deterministically. When you say "check all files," Claude checks a representative sample — and is convinced it checked everything. This is particularly insidious because as a user, you have no way to verify it without checking all the files yourself.
There's a second problem: LLM validation isn't reproducible. The same check in different sessions yields different results. Session A finds 12 issues, Session B finds 8 others, Session C finds 15 — overlapping but never identical. For a quality assurance system, that's unacceptable.
This becomes especially critical with template errors. A mistake in a template propagates to ALL specs based on that template. If the template defines "## References" instead of "## Links" as a section header, all new specs have the wrong header. And when Claude only spot-checks, it catches the problem in three files — but misses it in the other forty.
My validation went through four evolutionary stages:
Stage 1: Sampling
The starting point. "Check the consistency" — and Claude checks what it deems relevant. The problem: you don't notice that sampling is happening because Claude doesn't say "I checked 15 of 121 files." It says "Consistency is good, here are the issues." I discovered the problem only when my manual review of a file found the exact same issue that Claude had reported as fixed in another file. From that moment on, I never blindly trusted LLM validation again.
Stage 2: CLAUDE.md Rules
I wrote explicit rules into the CLAUDE.md: "For consistency checks, check ALL files, no sampling." It worked — partially. The number of issues found tripled, which initially looked like regression but was actually a quality gain: the problems were already there, now they just became visible. But: in new sessions, Claude forgets the context. The rules are only partially applied. And "check all files" with an LLM takes forever and burns tokens — with 121 feature specs plus Constitution and Plans, that's hundreds of file reads per run.
Stage 3: Dedicated Project Skill
A custom project skill with a clear mandate: which files, which checks, which tolerances. More structured than a CLAUDE.md rule because the skill contained the complete audit mandate and didn't depend on session context. But still LLM-based. The result was better — more consistent, more complete — but still not reproducible. Two invocations of the same skill yielded different results.
Stage 4: Bash Script + Minimal LLM Agents
The final solution separates deterministic from semantic checks. A bash script checks all 233 files in about 10 seconds for structural correctness: are the right headers present? Do section orderings match? Are references valid? Does formatting comply with standards? Do all specs have the mandatory sections? The script is deterministic — every run yields the exact same result. Today at 9 AM, tomorrow at 3 PM, next week — identical results, as long as the files haven't changed.
Only for semantic checks — "Is this description consistent with the architecture?", "Does this feature description still match the current data model?" — do 0 to 2 LLM agents come into play. Where reproducibility isn't critical because it's about interpretation, not facts. The separation is key: structure deterministic, semantics probabilistic. Not the other way around.

| Before (Stage 1) | After (Stage 4) |
|---|---|
| "Check consistency" | Bash script + 0-2 agents |
| Claude picks a sample | 100% of files, deterministic |
| ~42 parallel agents | 0-2 agents + script (~10 sec) |
| Different results per session | Reproducible |
The lesson: deterministic validation for structure. LLM only for semantics, where reproducibility isn't critical. Everything else is an illusion of quality assurance.
"Done" Is a Myth
One commit claimed "Consistency 10.0/10." Template compliance 100%. I remember the feeling: finally. Everything clean. Now I can implement. Then 200 more commits came — because the architecture kept evolving under the specs and ripped everything open again. Not because the earlier work was bad, but because a living project can't be frozen.
Schema changes were the biggest driver. Tables were renamed — payment_records became bookings because the new name better reflected the domain. Status values were consolidated because three different specs had three different status models for related entities. German enum values were migrated to English: MONATLICH became RECURRING because the codebase is English and mixed languages in enums cause confusion. Every single one of these changes was sensible. But every single one made dozens of specs inconsistent — because every spec referencing the old table, the old status, or the old enum had to be updated.
An existing feature with offline capability was a similar case. The feature already existed in the documentation, but its specs didn't meet SDD standards. Rust code in the Specify phase had to be migrated to mapping tables. Rule IDs had to be standardized. Not a new feature — but a complete refactoring pass for an existing one.
Then layer discipline — a problem that only became visible when preparing for Phase 4. Content must go into the right layer: UI details belong in UI specs, backend logic in backend specs. Sounds trivial. It isn't. I found backend validation rules in UI specs, UI flows in backend plans, database schema details in overview documents. Every wrong assignment becomes a problem during implementation — because Claude Code reads the spec and derives the wrong layer.
Block tagging was a response to that. Semantic tags for code blocks — ui, text, tree, chart — enable automated analysis. Instead of manually checking each block to see if it's in the right spec, a script can find all ui blocks and verify they're in a UI spec. Automation instead of manual control.
Sub-feature renumbering sounds like administrative work — and it is. Feature IDs like MV-002-R01 or filenames like pt-001-wizard.md need to remain stable when specs are restructured. But when a feature spec is split, the numbers change. And all references — in other specs, in plans, in the Constitution — need to be updated. With 233 files and cross-references, that's not a five-minute job.
And finally, design-first migration: applying SDD to itself. Instead of "just refactor" — first write a design document describing the change. Then a plan. Then execute. Applying the methodology to your own documentation. It sounds like overhead, but it saves time — because a well-thought-out refactoring produces less follow-up work than a spontaneous one. And it was an important insight: if the methodology isn't good enough to be applied to itself, it's not good enough for production code.
In total, the project now has 18 architectural patterns documented — from CRUD standards to complex synchronization patterns. Each pattern is a reference linked in mapping tables. The more patterns are documented, the less detail each individual spec needs. But every new pattern must be incorporated into existing specs. That drives commits too.
The core insight from these 477 commits: every improvement reveals new inconsistencies. That's not a bug — that's the process. The question isn't "When am I done?" but "When am I ready for the next step?"
What I Learned
Specify before Plan before Code. Enforce phase separation consistently. No code in Phase 2 (Specify), no code in Phase 3 (Plan). Code belongs exclusively in Phase 4 (Implement). 7,428 removed lines proved it. Writing code in specs means building up technical debt before the first line of production code even exists.
Deterministic validation beats LLM validation. A bash script checking 233 files in 10 seconds is more valuable than 42 parallel agents with inconsistent results. LLMs for semantics, scripts for structure. Relying on LLM validation alone is an illusion of quality assurance.
Template quality IS spec quality. A mistake in a template multiplies across every spec based on it. That makes template quality the single most critical factor in the entire SDD process. The best single investment is a clean, fully validated template.
Architecture changes ARE spec changes. When the data model changes, specs become inconsistent. That's unavoidable — but it must be planned for. Introducing a new feature or renaming a table means factoring in the resulting consistency work. Spec maintenance isn't finished when the feature is documented — it's finished when all affected specs are updated.
"Done" means ready for the next step. Not perfect. Not 10/10. The specs are consistent enough to implement from reliably. That's the benchmark. Anything above is perfectionism, anything below is risk.
Conclusion
651 commits. 233 documents. 121 feature specs. 14 constitution documents. 84 plans. Zero lines of production code.
Those are the numbers. The story behind them is one of a methodology that discovered itself. What started in 2025 as 5 DDD documents — a domain model, bounded contexts, ubiquitous language — grew through 21 initial commits, 153 commits in Part 2, and 477 more into a complete SDD Specify phase. From Domain-Driven Design to Spec-Driven Development. Not planned, but organic, over three phases and months.
Specify is now complete. The next step is Phase 3: Plan. The 121 feature specs are now being turned into refined implementation plans — the last mapping tables completed, criticality levels assigned, pattern references finalized. And only after that, for the first time in this project's history, code. The first commit with production code will be a special moment — after 651 commits of pure documentation.
It was never done. But it's ready. And that's enough.
Further Reading
- Part 1 of this series: Why the AI Era Needs Structured Specs — The theoretical foundations of SDD
- Part 2 of this series: SDD in Practice: Learnings from 153 Commits — The hands-on journey
- Claude Code Must-Haves: Claude Code Must-Haves — January 2026 — My curated setup for productive work
- GitHub Spec-Kit Repository: github.com/github/spec-kit — The open-source toolkit for SDD
- Thoughtworks SDD Article: Spec-Driven Development: Unpacking 2025 New Engineering Practices — The conceptual foundations
This is Part 3 of the SDD series. Part 1 explains the theoretical foundations: Why the AI Era Needs Structured Specs. Part 2 shows the hands-on journey: SDD in Practice: Learnings from 153 Commits.
This article was originally published on Medium.