Ich hatte 5 DDD-Dokumente. Eine API-Dokumentation, ein Domain Model, ein Operations Manual, eine Projektbeschreibung und eine Technische Architektur-Dokumentation. Zusammen bildeten sie das Fundament für ein Desktop-App-Projekt, das ich 2025 für eine Organisation aufgebaut hatte: Entity-Management, Resource-Management, Transaction-Tracking. 21 Commits in der DDD-Ära, sorgfältig strukturiert, mit Bounded Contexts und Ubiquitous Language. Das Domain Model hatte ich über 20 Iterationen von v1 bis v20 verfeinert.
Dann ruhte das Projekt. Ein ganzes Jahr lang. Der Stakeholder hatte andere Prioritäten, und die 5 Dokumente lagen in einem Git-Repository, unberührt. Bis Januar 2026.
Als ich es wieder aufnahm, war die Welt eine andere. Claude Code, GitHub Copilot und Cursor hatten AI-gestützte Entwicklung vom Experiment zum Alltag gemacht. Und ich stand vor einer Frage, die ich so nicht geplant hatte: Was mache ich mit meinen 5 DDD-Dokumenten in dieser neuen Welt? Wegwerfen und neu anfangen? Oder darauf aufbauen?
Das war keine normale SDD-Reise. Normalerweise würde niemand bestehende DDD-Dokumentation auf einen neuen Entwicklungsansatz umstellen. Aber genau das passierte — und die Erfahrung zeigt, warum strukturierte Specs in der AI-Ära unverzichtbar sind.
Das Problem: Vibe Coding vs. Struktur
"Generiere mir eine Entity-Verwaltung mit Rollen und Permissions." 30 Sekunden, 500 Zeilen Code. Es funktioniert. Größtenteils. Aber warum hat der Agent genau diese Architektur gewählt? Welche Edge Cases fehlen? Und warum SQLite statt PostgreSQL? Frag den Agent — er weiß es selbst nicht mehr, weil er keine explizite Entscheidung getroffen hat.
Willkommen im Paradox der AI-gestützten Entwicklung. GitHub Copilot, Claude Code und Cursor machen Code-Generierung trivial. Ein Prompt, wenige Sekunden, funktionierender Code. Aber unsere Projekte werden dadurch nicht automatisch besser. Was passiert, wenn du so arbeitest, hat einen Namen: Vibe Coding. Code ohne Plan. Prompts ohne Kontext. Architektur per Zufall.
Die Probleme sind real und wiederkehrend. Nicht-deterministisches Verhalten bedeutet, dass der gleiche Prompt unterschiedlichen Code erzeugt. Heute bekommst du eine saubere Repository-Schicht, morgen ein God Object. Führe denselben Prompt zweimal aus und du bekommst zwei verschiedene Architekturen. Das ist kein Bug — es liegt in der Natur von Large Language Models. Aber es macht "einfach drauflos prompten" zu einem Glücksspiel.
Kontext-Verlust bei längeren Sessions verschärft das Problem. Der Agent vergisst nach dem dritten Feature, welche Architektur-Entscheidungen du am Anfang getroffen hast. Feature A nutzt ein Repository-Pattern, Feature B umgeht die Datenbankschicht komplett, Feature C erfindet ein eigenes Error-Handling. Jedes Feature für sich funktioniert — aber zusammen ergibt sich kein kohärentes System.
Und Architekturentscheidungen emergieren zufällig statt bewusst — REST oder GraphQL, SQLite oder PostgreSQL, Monolith oder Microservices. Der Agent trifft diese Entscheidungen für dich, basierend auf dem, was statistisch am häufigsten in seinen Trainingsdaten vorkam. Nicht basierend auf den Anforderungen deines Projekts, nicht basierend auf den Constraints deiner Organisation, nicht basierend auf den Erwartungen deiner User.
Das Kernproblem liegt tiefer: Code-Generierung ist nicht der Bottleneck. Jedes AI-Tool kann Code schneller schreiben als du denken kannst. Der eigentliche Bottleneck liegt im Verstehen, Entscheiden und Strukturieren. Welche Features braucht der User? Wie hängen sie zusammen? Welche Constraints gelten? Welche Architektur trägt langfristig? Wer versteht den generierten Code in drei Monaten noch? Diese Fragen beantwortet kein Prompt von allein.
Spec-Driven Development dreht den Prozess um: Erst denken, dann generieren. Erst definieren, was gebaut werden soll, dann die AI den Code schreiben lassen. Das klingt offensichtlich. Ist es aber in der Praxis nicht — weil die Geschwindigkeit der Code-Generierung dazu verführt, das Denken zu überspringen.
Was ist SDD?
Spec-Driven Development — kurz SDD — ist ein Entwicklungsansatz, bei dem gut gestaltete Software-Anforderungsspezifikationen als Prompts für AI-Coding-Agenten genutzt werden. Die Kernidee: Specifications werden executable. Sie beschreiben nicht nur, was gebaut werden soll, sondern werden direkt zur Grundlage funktionsfähiger Implementierungen. Die Spec ist der Prompt — nur strukturiert, vollständig und bewusst formuliert.
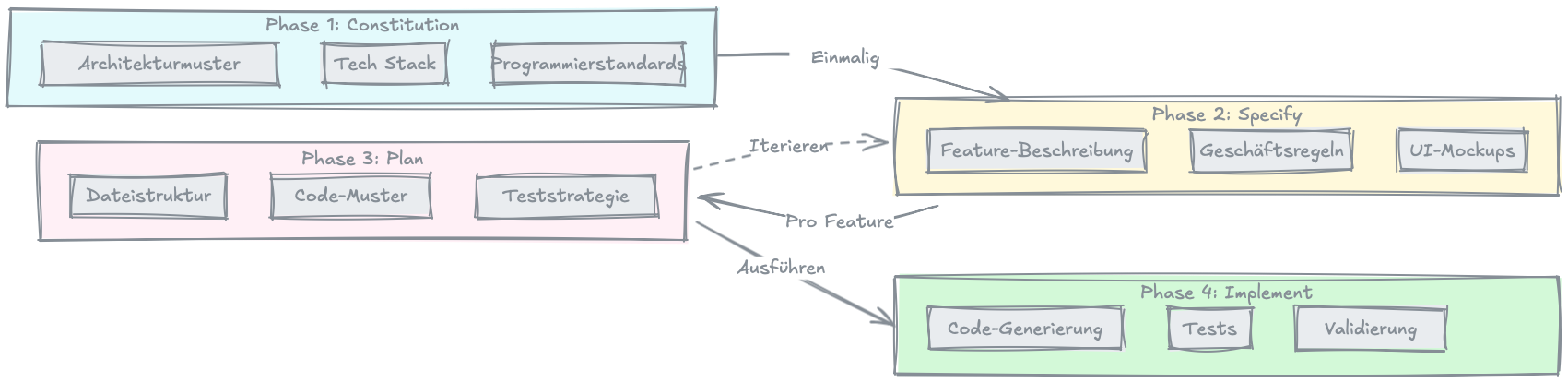
SDD folgt vier Phasen:
1. Constitution — das Projektfundament
Die Constitution wird einmal pro Projekt erstellt und definiert die Grundlagen: Architektur-Patterns, Tech-Stack, Design-Prinzipien und Coding-Standards. Sie ist das Regelwerk, auf das sich alle weiteren Entscheidungen beziehen. Denk daran wie an die Verfassung eines Landes — sie ändert sich selten, aber alles andere leitet sich von ihr ab.
Bei meinem Desktop-App-Projekt wurde die DDD-Constitution zum Fundament der SDD-Constitution. Die drei Bounded Contexts — System/IAM, Entity-Management und Resource-Management — definierten die Architektur. Die Ubiquitous Language aus dem Domain Model wurde zur Terminologie in den Specs.
2. Specify — WAS wird gebaut
Pro Feature wird beschrieben, was gebaut werden soll: Business-Regeln, UI-Mockups, Szenarien. Bewusst ohne technische Implementierungsdetails. Kein Wort über Datenbank-Schemas oder API-Endpoints. Nur reine Business-Logik in der Sprache der Domäne.
Warum diese Trennung? Weil technische Details in der Specify-Phase die AI in eine bestimmte Richtung drängen, bevor die fachlichen Anforderungen vollständig verstanden sind. Wenn du in der Spec bereits "PostgreSQL" erwähnst, wird der Agent seine gesamte Implementierung darauf ausrichten — auch wenn SQLite für deinen Use Case besser geeignet wäre.
3. Plan — WIE wird es umgesetzt
Jetzt kommt die technische Strategie: Welche Dateien werden erstellt? Welche Patterns kommen zum Einsatz? Wie sieht die File-Struktur aus? Welche Mapping-Tabellen verbinden Business-Konzepte mit technischen Strukturen? Der Plan referenziert die Constitution für übergreifende Entscheidungen und die Spec für die fachlichen Anforderungen — aber er enthält keinen Code. Er beschreibt die Strategie, nicht die Implementierung.
4. Implement — Code-Generierung durch AI
Erst jetzt wird Code geschrieben. Der AI-Agent arbeitet auf Basis von Constitution, Specs und Plans. Er hat den vollen Kontext: was das Projekt ist (Constitution), was gebaut werden soll (Specify) und wie es technisch umgesetzt wird (Plan). Das ist der entscheidende Unterschied zu Vibe Coding: Der Agent generiert nicht ins Blaue hinein, sondern auf einer dokumentierten, bewusst getroffenen Grundlage.
Abgrenzung zu Waterfall
SDD wird oft reflexartig mit Waterfall verglichen. "Das ist doch Big Design Upfront!" Dieser Einwand greift zu kurz. Die Unterschiede sind fundamental:
| Aspekt | Waterfall | SDD |
|---|---|---|
| Feedback-Loop | Lang (Monate) | Kurz (Stunden/Tage) |
| Flexibilität | Starr (Big Design Upfront) | Iterativ (Feature-by-Feature) |
| AI-Integration | Keine | Zentral |
| Risiko | Spätes Scheitern | Frühe Validierung |
| Dokumentation | Oft veraltet | Living Documentation |
Der entscheidende Unterschied: SDD ist iterativ. Du spezifizierst ein Feature in wenigen Stunden, implementierst es, validierst das Ergebnis, und gehst zum nächsten Feature. Constitution wird einmal geschrieben. Specify und Plan werden pro Feature durchlaufen. Das Feedback kommt früh und häufig — nicht erst nach Monaten.
Abgrenzung zu TDD
Auch Test-Driven Development wird als Vergleich herangezogen. Beide Ansätze betonen "erst denken, dann implementieren", aber auf unterschiedlichen Ebenen. TDD definiert, wie getestet wird — auf Code-Ebene, mit konkreten Assertions für einzelne Funktionen. SDD definiert, was gebaut wird — auf Feature-Ebene, mit Business-Regeln und Szenarien. Die beiden Ansätze schließen sich nicht aus, sondern ergänzen sich: SDD liefert die Grundlage dafür, welche Tests geschrieben werden sollten, und TDD stellt sicher, dass die Implementierung korrekt ist.
Externe Standards
Ich habe SDD nicht nach Lehrbuch gelernt. Mein Workflow entstand organisch, aus der Arbeit mit DDD-Dokumenten und AI-Agenten. Erst als ich die externen Standards las, wurde mir klar, dass mein Workflow bereits SDD war. Diese Standards haben meine Arbeit validiert — und mir gezeigt, dass andere unabhängig zu denselben Prinzipien gekommen sind.
GitHub Spec-Kit
GitHub hat mit Spec-Kit ein Open-Source-CLI-Tool veröffentlicht, das SDD konkret umsetzbar macht. Es ist technologieagnostisch, funktioniert mit mehr als 16 AI-Agenten — von Claude Code über GitHub Copilot bis Cursor — und strukturiert den Entwicklungsprozess mit 5 Kern-Commands: constitution, specify, plan, tasks und implement. Spec-Kit ist kein Code-Generator, sondern ein Prozess-Framework mit Guardrails und Organisationsprinzipien. Das Besondere: Es zwingt dich nicht zu einem bestimmten Tech-Stack oder einer bestimmten Architektur. Es strukturiert nur den Prozess — die Reihenfolge, in der du über dein Projekt nachdenkst.
Thoughtworks SDD-Artikel
Im Dezember 2024 veröffentlichte Thoughtworks den Artikel "Spec-Driven Development: Unpacking 2025 New Engineering Practices". Er definiert 5 Kernprinzipien, die den konzeptionellen Rahmen für SDD bilden:
- Kürzere Feedback-Loops — Stunden und Tage statt Monate. Ein Feature spezifizieren, implementieren, validieren, wiederholen.
- Strukturierte Anforderungsanalyse — Gegen "Vibe Coding". Formalisierte Specs statt vager Prompts.
- Domänenorientierte Sprache — Specs in der Sprache des Business, nicht in Technik-Jargon.
- Vollständigkeit bei Knappheit — Den kritischen Pfad erfassen, nicht jede erdenkliche Edge-Case. So viel wie nötig, so wenig wie möglich.
- Trennung Business/Tech — WAS wird gebaut (Specify) und WIE wird es umgesetzt (Plan) bewusst voneinander trennen.
Thoughtworks betont dabei ehrlich, dass SDD experimentell ist. Evaluationsmethoden für "gute Specs" fehlen noch. Die Frage, ob Specs oder Code das primäre Artefakt sind, ist nicht abschließend geklärt. Aber die Richtung stimmt.
Addy Osmani
Addy Osmani beschreibt in seinem AI-Coding-Workflow einen verwandten Ansatz aus der Perspektive eines Google-Engineers. Er betont strukturierte Prompts und iterative Verfeinerung — kein blindes "generiere mir Code", sondern ein bewusster Prozess mit klarem Kontext und expliziten Constraints. Sein Workflow ergänzt SDD um die praktische Dimension: Wie arbeitet man effektiv mit AI-Agenten, wenn die Specs stehen? Wie iteriert man, wenn das erste Ergebnis nicht passt?
Alle drei Quellen — GitHub, Thoughtworks und Osmani — kommen unabhängig voneinander zum selben Schluss: Strukturierte Spezifikationen sind der Schlüssel zu wartbarem AI-generiertem Code. Das ist kein Zufall, sondern eine Konvergenz, die zeigt, dass die Industrie ein echtes Problem erkannt hat.
DDD als Fundament für SDD
Mein Weg zu SDD war ungewöhnlich, weil ich bereits ein Domänenmodell hatte, bevor SDD überhaupt ins Spiel kam. Die 5 DDD-Dokumente — über ein Jahr lang sorgfältig aufgebaut — wurden zum Fundament der SDD-Constitution. Das war keine bewusste Entscheidung — es ergab sich aus der Natur der Dokumente. Sie enthielten bereits alles, was eine Constitution braucht: Architektur-Grenzen, eine gemeinsame Sprache und ein Verständnis für die Domäne.
Bounded Contexts wurden zur Constitution-Struktur. Meine drei Bounded Contexts — System/IAM, Entity-Management und Resource-Management — definierten direkt die Gliederung der Constitution. Jeder Context bekam seinen eigenen Abschnitt mit eigenen Architektur-Entscheidungen, eigenen Permissions und eigenen Datenmodellen. Die Grenzen zwischen den Contexts waren bereits gezogen. SDD musste sie nur übernehmen.
Ubiquitous Language wurde zur Spec-Terminologie. Die Fachsprache aus dem Domain Model floss direkt in die Feature-Specs. Wenn das Domain Model von "Entities" sprach, verwendeten die Specs denselben Begriff. Wenn es "Transactions" sagte, stand in der Spec "Transactions" — nicht "Buchungen", nicht "Vorgänge", nicht "Operationen". Keine Übersetzung, keine Interpretation. Die Sprache war bereits definiert, konsistent und von allen Beteiligten verstanden. Das ist genau das, was Thoughtworks mit "domänenorientierter Sprache" meint — nur dass ich sie nicht für SDD entwickelt hatte, sondern sie aus DDD mitbrachte.
Das Domain Model zeigte die Feature-Zusammenhänge. Die v1-bis-v20-Iterationen des Domain Models hatten mir über Monate gezeigt, wie Features natürlich zusammenhängen. Welche Entitäten voneinander abhängen. Welche Operationen transaktional sein müssen. Welche Validierungen geschäftskritisch sind. Dieses Wissen floss in die Specify-Phase — nicht als abstraktes Wissen, sondern als konkrete Business-Regeln und Szenarien.
Die Kernaussage: DDD liefert das WAS des Business. SDD strukturiert das WIE für AI. DDD definiert die Domäne, die Sprache, die Grenzen. SDD nimmt dieses Wissen und macht es für AI-Agenten konsumierbar — in Constitutions, Specs und Plans. Die beiden Ansätze ergänzen sich, weil sie auf unterschiedlichen Ebenen arbeiten: DDD ist ein Design-Ansatz für die Domäne, SDD ist ein Workflow-Ansatz für die AI-gestützte Entwicklung.
Das ist der ungewöhnliche Teil meiner SDD-Reise: Ich hatte bereits ein durchdachtes, über 20 Iterationen verfeinertes Domänenmodell. Das hat den Einstieg in SDD erheblich beschleunigt. Die Constitution musste nicht von Null aufgebaut werden. Die Fachsprache musste nicht erst definiert werden. Die Feature-Grenzen waren bereits klar.
Wer ohne DDD-Vorarbeit startet, wird diese Schritte in der Constitution-Phase nachholen müssen. Das bedeutet nicht, dass du zuerst DDD lernen musst, um SDD zu nutzen. Aber es bedeutet, dass die Constitution-Phase gründlich sein sollte: Definiere deine Domäne, deine Sprache, deine Architektur-Grenzen. Dieser initiale Aufwand zahlt sich bei jedem weiteren Feature zurück — weil jede Spec und jeder Plan auf diesem Fundament aufbaut.
Fazit und Ausblick
Spec-Driven Development ist kein Silver Bullet. Es löst nicht alle Probleme der AI-gestützten Entwicklung. Nicht-deterministische Code-Generierung bleibt eine Herausforderung. Specs können veralten, wenn sie nicht bewusst synchronisiert werden. Evaluationsmethoden für "gute Specs" stecken noch in den Kinderschuhen.
Aber SDD ist ein strukturierter Gegenentwurf zu "Vibe Coding". Statt vage Prompts an AI-Tools zu werfen und auf das Beste zu hoffen, definierst du bewusst, was gebaut werden soll, bevor du die AI arbeiten lässt. Du trennst Business-Anforderungen von technischer Implementierung. Du schaffst Living Documentation, die nicht nach dem ersten Sprint veraltet. Und du gibst dem AI-Agenten den Kontext, den er braucht, um konsistenten, architekturkonformen Code zu generieren.
Die externen Standards — GitHub Spec-Kit, Thoughtworks und Addy Osmani — zeigen, dass die Industrie unabhängig zu denselben Prinzipien findet. Das ist kein Zufall. Die AI-Ära braucht strukturierte Specs, weil die Alternative — ungeplante Code-Generierung im großen Stil — zu genau den Problemen führt, die aus der Pre-AI-Ära bekannt sind: Tech-Debt, inkonsistente Architektur, unwartbarer Code. Nur schneller.
SDD ist nicht perfekt. Es erfordert Disziplin, Specs aktuell zu halten. Es erfordert die Bereitschaft, Zeit in Dokumentation zu investieren, bevor Code entsteht. Aber es ist ein Schritt in die richtige Richtung — weg vom reaktiven Prompten, hin zum bewussten Gestalten.
Die 5 DDD-Dokumente waren der Anfang. Was daraus wurde, hat mich selbst überrascht.
Im nächsten Teil zeige ich, wie ich SDD organisch entdeckte — in 153 Commits und 10 Tagen. Nicht nach Lehrbuch, sondern durch Learning-by-Doing mit Claude Code als einzigem Werkzeug. Von chaotischer Dokumentation zu einem konsistenten System, das tatsächlich funktioniert. Ich zeige die Fehler, die Refactorings und die Aha-Momente — ungefiltert.
Und in Teil 3: Warum 651 Commits später immer noch keine Zeile Produktivcode existiert — und warum das genau richtig ist. Spoiler: "Fertig" ist ein Mythos, wenn Qualität das Ziel ist.
Further Reading
- Teil 2 dieser Serie: SDD in der Praxis: Learnings aus 153 Commits — Die praktische Umsetzung
- Teil 3 dieser Serie: 651 Commits, 0 Zeilen Code — Warum "fertig" ein Mythos ist — Von 153 zu 651 Commits
- Claude Code Must-Haves: Claude Code Must-Haves - Januar 2026 — Mein kuratiertes Setup für produktives Arbeiten
- Superpowers Skills: github.com/svens-uk/superpowers — Custom Skills für strukturierte AI-Workflows
- GitHub Spec-Kit Repository: github.com/github/spec-kit — Das Open-Source-Toolkit für SDD
- Thoughtworks SDD-Artikel: Spec-Driven Development: Unpacking 2025 New Engineering Practices — Die konzeptionellen Grundlagen
- Addy Osmani AI-Coding-Workflow: addyosmani.com/blog/ai-coding-workflow — Verwandter Workflow-Ansatz
Dies ist Teil 1 der SDD-Serie. Teil 2 zeigt die praktische Umsetzung: SDD in der Praxis: Learnings aus 153 Commits. Teil 3 beschreibt die Reifephase: 651 Commits, 0 Zeilen Code — Warum "fertig" ein Mythos ist.
Dieser Artikel erschien ursprünglich auf dem Mayflower Blog.