Tag 5 eines Desktop-App-Projekts. Ich schaue auf mein docs/-Verzeichnis: 102 Markdown-Dateien. Templates, Patterns, Feature-Specs. Dann lese ich nochmal den Thoughtworks-Artikel über SDD — "Constitution → Specify → Plan" — und plötzlich klickt es: Das, was ich die letzten Tage gebaut habe, IST Spec-Driven Development. Ich habe es gemacht, ohne es zu wissen.
Im ersten Teil dieser Serie habe ich erklärt, was SDD ist und warum AI-Agenten strukturierte Spezifikationen brauchen. Theorie ist wichtig — aber wie sieht das in der Praxis aus? Hier ist meine authentische Geschichte: 153 Commits, 4 Phasen, 10 Tage. Kein perfekter Plan, sondern Learning-by-Doing.
| Phase | Zeitraum | Commits | Was passierte |
|---|---|---|---|
| 1. Feature-Blitz | 19.-21. Jan | 18 | 18 Features dokumentiert — schnell, aber inkonsistent |
| 2. Framework-Emergenz | 22.-24. Jan | 27 | Templates, Patterns, Reference-Style entdeckt |
| 3. SDD-Epiphanie | 25.-26. Jan | 79 | Constitution → Specify → Plan erkannt und umgesetzt |
| 4. Finalisierung | 27. Jan | 29 | Audit, Cleanup, 9.8/10 Konsistenz erreicht |
Der Kontext
Dezember 2024 fragte mich der stellvertretende Abteilungsleiter einer Organisation nach einer Desktop-Anwendung. Entity-Management, Resource-Management, Transaction-Tracking — das volle Programm. Ich begann die Dokumentation auszuarbeiten, damals noch mit RooCode, später mit Claude. Es wurde umfangreicher als gedacht. Im Januar 2025 entstanden die ersten Commits, dann ruhte das Projekt ein ganzes Jahr.
Im Januar 2026 meldete er sich wieder. Er hatte zwischenzeitlich mit ChatGPT experimentiert, war an Python auf Windows gescheitert. Ich griff das Projekt wieder auf — dieses Mal mit Claude Code und einem radikalen Prinzip: Ich schreibe keine Zeile Code selbst. Alles geht durch Claude Code. Ich reviewe, validiere, iteriere — aber tippe nicht selbst.
5 DDD-Dokumente existierten bereits aus 2025: Domain Model (v1-v20), Bounded Contexts, Ubiquitous Language, technische Architektur und eine Projektbeschreibung. 21 Commits, ein ganzes Jahr alt. Diese DDD-Basis lieferte die Domänen-Struktur — Entity-Management, Transaction-Management, Resource-Management — aber keine Spec-Struktur für AI-gestützte Entwicklung.
Die erste Aufgabe war, diese DDD-Dokumentation in eine Feature-Spezifikation zu überführen. Dabei fiel schnell auf, dass die ursprünglich geplante PWA mit Microservice-Architektur zu komplex war. Also Architekturwechsel: Eine Tauri Desktop-App mit Svelte und Rust. Local-First statt Cloud-First, SQLite statt PostgreSQL. Weniger Infrastruktur, schnellere Entwicklung.
Von SDD hatte ich zu diesem Zeitpunkt gehört (Q4 2025), aber noch nicht wirklich verstanden. Meine Arbeitsweise waren strukturierte Dialoge mit Claude Code. Eine Session hatte 106 Nachrichten, eine andere sogar 263. Es war kein "generiere mir Code", sondern echtes Ping-Pong. Claude fragte zurück: "Ist die Entity-Verwaltung in diesem Umfang relevant?" — "Welche Aspekte sollten vereinfacht werden?" Feature für Feature durchgearbeitet, Entscheidungen im Dialog getroffen.

Phase 1: Der Feature-Blitz
Die ersten drei Tage waren ein Sprint. Mein Ziel: Die alte Dokumentation in einen Implementierungsplan umschreiben. Claude Code als Co-Autor, ich als Dirigent. Das Commit-Log erzählt die Geschichte:
IAM-001: First-Run Setup vollständig spezifiziert
IAM-002: Benutzerverwaltung vollständig spezifiziert
EM-001: Entity-Management vollständig spezifiziert
TM-001: Transaction-Model-Management vollständig spezifiziert
RM-001: Resource-Management vollständig spezifiziert
...
18 Features in 3 Tagen, verteilt auf vier Bounded Contexts: Identity & Access Management, Entity-Management, Transaction-Management und Resource-Management.
Die Domänen-Struktur aus meiner früheren DDD-Arbeit bewährte sich. Architektur-Entscheidungen entstanden im Dialog — der Wechsel von PWA auf Desktop-App kam durch Claudes Rückfragen zur Komplexität. "Status-Typen reduzieren, Adressverwaltung optional, keine komplexe Familienverknüpfung" — solche Vereinfachungen emergierten aus dem Gespräch.
Was schief lief: Keine konsistente Template-Struktur. Specs wurden zu lang, manche über 1.500 Zeilen. Inkonsistente Pattern-Verwendung — manche UI-Specs hatten DataTables, manche nicht. Keine Trennung zwischen WAS und WIE. Am 21. Januar abends schaute ich auf die Specs: 18 Dokumente, aber jedes ein bisschen anders. Die Entity-Verwaltung hatte 2.361 Zeilen, die Navigation nur 300. Welches war jetzt der Standard? Ich brauchte Struktur.
Phase 2: Die Framework-Emergenz
Der Trigger war simpel: "Das muss strukturierter sein." Noch dachte ich nicht an SDD. Ich löste Probleme. Und dabei emergierten Patterns — organisch, nicht geplant.
Am 22. Januar die Wizard-Standardisierung. Problem: 5 verschiedene Wizard-Specs, alle unterschiedlich strukturiert. Lösung: Ein Universal Wizard Pattern als Template.
Am 23. Januar der Game-Changer: Die Reference-Style Entdeckung. entities-backend.md hatte 2.361 Zeilen. Zu viel Code in der Spec. Vollständige Implementierungen — if-statements, loops, error handling. Alles drin. Aber warum? Ich brauche keine vollständigen Implementierungen in Specs. Ich brauche nur genug Information, damit Claude Code den Rest bauen kann.
Die Lösung war das Reference-Style Pattern. Statt ~70 Zeilen pro Funktion mit vollständiger Implementierung nur noch ~15 Zeilen: Function Signature plus Metadata-Tabelle. Permission, Validierung, Repository, Activity Log — mehr braucht Claude Code nicht. Der Rest ist Implementierungsdetail. Ergebnis: entities-backend.md schrumpfte von 2.361 auf 818 Zeilen. Minus 65 Prozent.
Am 24. Januar das Template-System v3.0. Jetzt hatte ich Patterns, aber jede Spec-Art brauchte ihre eigene Struktur. Also entwickelte ich 6 Template-Typen: Overview, UI, Implementation, Testing, Pattern, System. Gleichzeitig Pattern-Integration v2.0 — statt einer zentralen Pattern-Liste am Anfang jeder Spec kamen die Pattern-Verweise jetzt direkt an die relevante Stelle. Der Unterschied: Bei v1.0 musste ich nach oben scrollen, um zu sehen welches Pattern gilt. Bei v2.0 steht es direkt da, wo es relevant ist.
Stand Ende Phase 2: 102 Specs dokumentiert, Templates v3.0 etabliert, Reference-Style funktioniert, Konsistenz gefühlt 7/10. Ich dachte, ich baue ein Dokumentations-Framework. Mir war nicht klar: Das IST Spec-Driven Development.
Phase 3: Die SDD-Epiphanie
Morgens, 25. Januar. Ich lese nochmal den Thoughtworks-Artikel über SDD. "Constitution → Specify → Plan" steht da. Ich schaue auf meine Ordnerstruktur: docs/specs/. Plötzlich klickt es: Meine Templates v3.0 sind die Specify-Phase (WAS). Meine Implementation-Specs sollten die Plan-Phase sein (WIE). Meine architecture.md — das ist Constitution! Ich habe SDD gebaut, ohne es zu wissen. Das war keine typische SDD-Adoption. Normalerweise startet man mit Constitution, dann Specify, dann Plan. Ich hatte bereits 18 Features dokumentiert und entdeckte erst dann, dass das, was ich tat, einen Namen hat. SDD retrospektiv auf bestehende Dokumentation anzuwenden — das beschreibt kein Lehrbuch. Aber es war noch nicht richtig getrennt.
Die Umstrukturierung dauerte 12 Stunden: Ein 1.125-Zeilen-Blueprint, 97 Specs in neue Verzeichnisse migriert, 500+ Referenzen aktualisiert. Das Ergebnis war eine klare Drei-Phasen-Struktur: constitution/ für die Architektur (9 Docs), specify/ für das WAS (88 Docs), plans/ für das WIE (Design-Docs).
52 Commits am 25. Januar. 27 Commits am 26. Januar. 79 Commits in zwei Tagen. Das war intensiv. Ich habe von 9 Uhr morgens bis 21 Uhr abends gearbeitet, mit kurzen Pausen. Claude Code hat jeden Commit erstellt — ich habe reviewed, korrigiert, iteriert, aber nichts selbst getippt.
Die Metriken nach der Transformation: Konsistenz von 7/10 auf 9.8/10. Error-Handling Compliance von 14/16 auf 15/15. Wizard-Struktur von 4/5 auf 5/5.
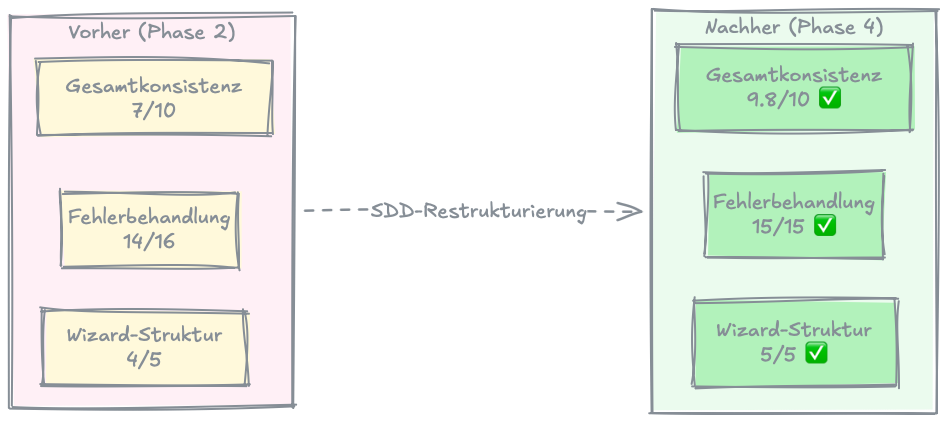
Phase 4: Die Finalisierung
Der letzte Schliff. Ich hatte die große Transformation gemacht, aber jetzt brauchte es einen vollständigen Audit. Jede Spec auf korrekte Permission-Referenzen geprüft, fehlende ergänzt. Error-Handling standardisiert — vorher existierten 7 verschiedene Varianten in den Specs (Error Enum, Error Handling, Fehlerbehandlung, Error-Handling, Errors...), nachher 2 Standards: Backend nutzt Error Enum, Frontend nutzt Error Handling, dokumentiert in ADR-0002.
Implizite Business-Regeln finden und explizit dokumentieren. Redundanzen zwischen CLAUDE.md und README.md eliminieren. 141 broken @-mentions nach der großen Migration gefunden und gefixt. 38 Spec-Dokumente hatten keine Verweise-Sektion — ergänzt.
Finale Konsistenz: 9.9/10. Das letzte 0.1 fehlt, weil Perfektion ein Mythos ist.
Was ich gelernt habe
SDD-Prinzipien emergieren oft organisch. Ich habe nicht mit "Jetzt mache ich SDD" angefangen. Ich habe Probleme gelöst, Struktur gesucht, Templates entwickelt. Am Ende war es SDD — aber ich habe es im Prozess gelernt. Das ist vielleicht der wichtigste Punkt: Du musst nicht perfekt planen, bevor du anfängst. Du kannst anfangen, iterieren, und die Methodik im Prozess entdecken.
Das Reference-Style Pattern war die größte Einzelverbesserung. Nur Function Signatures plus Metadata-Tabellen statt vollständiger Implementierungen. Minus 65 Prozent Größenreduktion, bessere Scanbarkeit. Pattern-Verweise gehören direkt zur relevanten Sektion — nicht in eine zentrale Liste am Anfang. 200 Zeilen später weiß sonst niemand mehr, welches Pattern gilt.
Interaktive Dialoge mit Claude Code waren entscheidend. Die längste Session hatte 263 Nachrichten. Claude fragte zurück, stellte die richtigen Fragen, half bei Architektur-Entscheidungen. Der Wechsel von PWA auf Desktop-App entstand in so einem Dialog. Das ist kein Einmal-Prompt-und-fertig, sondern echte Zusammenarbeit.
Templates früh definieren spart Refactoring. Hätte ich nach Feature 3 Templates definiert, hätte ich 15 Features nicht nachträglich anpassen müssen. Und SDD funktioniert auch retrospektiv — ich hatte schon 18 Features dokumentiert (Phase 1), dann kam die SDD-Struktur (Phase 2-4). Nicht "Alles wegwerfen und neu anfangen", sondern bestehende Docs migrieren.
Was ich anders machen würde
SDD-Prinzipien vor dem Start verstehen wäre hilfreich gewesen — aber Learning-by-doing war authentisch. Manchmal muss man die Fehler machen, um zu verstehen warum die Methodik existiert. Metriken von Anfang an tracken hätte den Fortschritt sichtbarer gemacht. Kleinere Commits wären besser gewesen — 79 Commits in zwei Tagen war zu viel auf einmal. Und ein zweites Augenpaar hätte wahrscheinlich früher gesehen, dass ich SDD baue ohne es zu wissen.
Empfehlungen
Wenn du SDD ausprobieren willst: Start simple. Beginne mit einer constitution.md und 1-2 Feature-Specs. Nicht 18 Features auf einmal wie ich. Lerne das System mit einem kleinen Scope, dann skaliere. Nach dem zweiten oder dritten Feature solltest du ein Template haben. Welche Sektionen braucht jede Spec? Was ist MUSS, was ist KANN? Wie referenziere ich andere Specs?
Perfekt gibt es nicht. Deine erste Template-Version wird nicht die letzte sein. Ich hatte v1.0, v2.0, v3.0 — und v3.0 ist immer noch nicht perfekt. Definiere einen Konsistenz-Score, auch wenn er subjektiv ist. "7/10 → 9.8/10" ist motivierender als "es fühlt sich besser an".
Claude Code ist hervorragend für Spec-Arbeit. Strukturierte Dokumente, klare Regeln, iteratives Verfeinern — genau das was AI gut kann. Nutze es.
Fazit
SDD ist keine perfekte Methodik. Es ist eine strukturierte Alternative zum chaotischen "Vibe Coding", das manche AI-Entwicklung dominiert. Der Kern bleibt simpel: Erst spezifizieren, dann implementieren. Constitution definiert das System. Specify beschreibt WAS. Plan beschreibt WIE. Und erst dann kommt Code.
Du musst SDD nicht von Anfang an perfekt machen. Du kannst anfangen, iterieren, und die Methodik im Prozess entdecken. Das Ergebnis ist das gleiche: Strukturierte Spezifikationen, die AI-Agenten verstehen und umsetzen können.
Further Reading
- Teil 1 dieser Serie: Warum die AI-Ära strukturierte Specs braucht — Die theoretischen Grundlagen von SDD
- Teil 3 dieser Serie: 651 Commits, 0 Zeilen Code — Warum "fertig" ein Mythos ist — Von 153 zu 651 Commits — und warum keine Zeile Code existiert
- Claude Code Must-Haves: Claude Code Must-Haves - Januar 2026 — Mein kuratiertes Setup für produktives Arbeiten
- Superpowers Skills: github.com/svens-uk/superpowers — Custom Skills für strukturierte AI-Workflows
- GitHub Spec-Kit Repository: github.com/github/spec-kit — Das Open-Source-Toolkit für SDD
- Thoughtworks SDD-Artikel: Spec-Driven Development: Unpacking 2025 New Engineering Practices — Die konzeptionellen Grundlagen
Dies ist Teil 2 der SDD-Serie. Teil 1 erklärt die theoretischen Grundlagen: Warum die AI-Ära strukturierte Specs braucht. Teil 3 beschreibt die Reifephase: 651 Commits, 0 Zeilen Code — Warum "fertig" ein Mythos ist.
Dieser Artikel erschien ursprünglich auf dem Mayflower Blog.