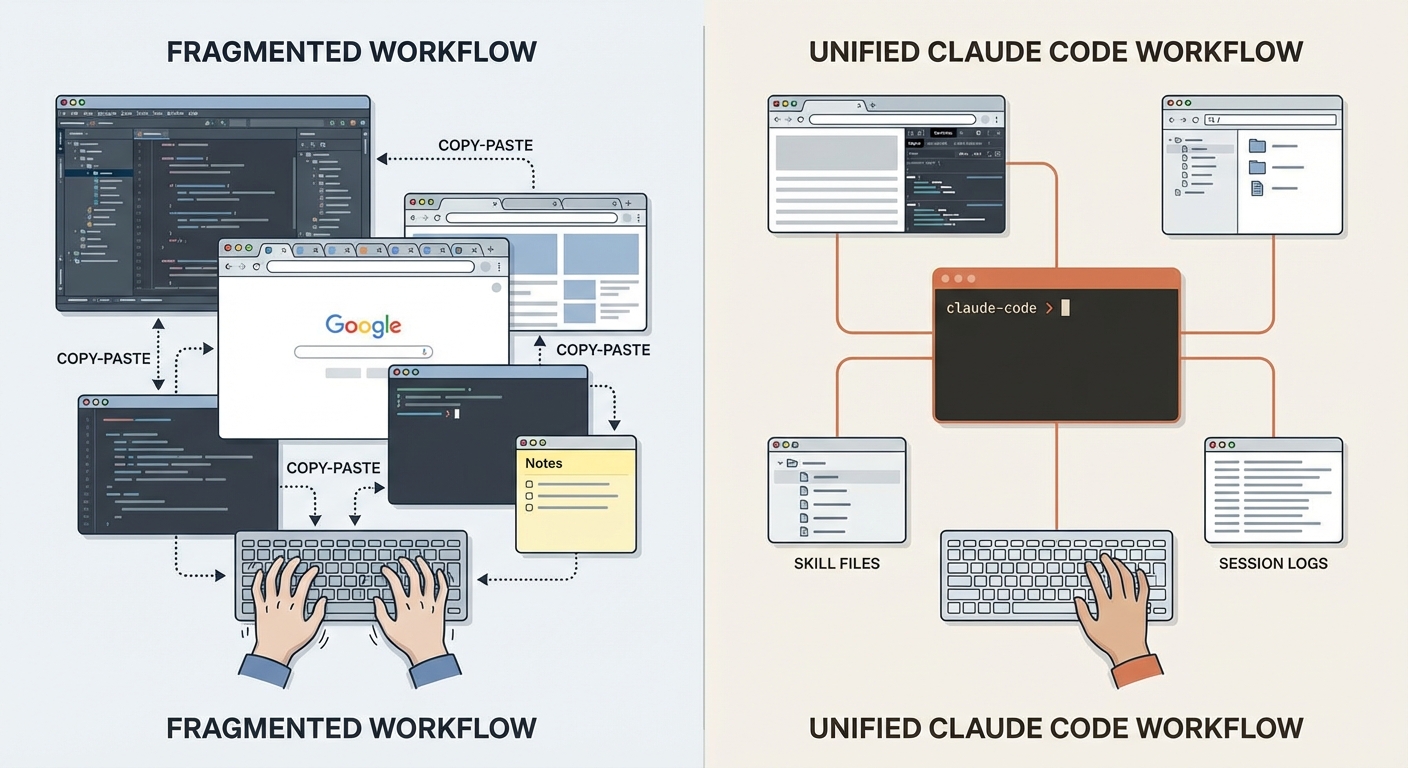
Irgendwann ist mir aufgefallen, dass ich kaum noch eine IDE öffne. Kein bewusster Entschluss – es hat sich einfach so ergeben. Und die kleinen Wegwerf-Scripts, die ich früher schnell selbst getippt hätte? Die schreibt jetzt Claude Code. Schneller, und meistens besser – weil er den vollen Kontext der gerade laufenden Arbeit hat.
Was passiert, wenn Claude Code aufhört, ein Tool zu sein und zur primären Arbeitsumgebung wird? Das ist keine rhetorische Frage. Es ist eine Verschiebung, die sich bei mir über Wochen vollzogen hat – nicht durch eine bewusste Entscheidung, sondern durch ein langsames Aufhören. Irgendwann habe ich die IDE nicht mehr geöffnet. Nicht aus Prinzip. Sondern weil der Umweg über sie keinen Mehrwert mehr hatte.
Die tiefere Veränderung zeigt sich an einer Kleinigkeit: Claude schreibt mir am Ende von Aufgaben Scripts on-demand – besser als die schnellen Wegwerf-Scripts, die ich selbst geschrieben hätte. Nicht weil Claude schlauer ist, sondern weil er den vollen Kontext der gerade abgeschlossenen Arbeit hat.
Das ist kein Artikel über neue Features. Es ist eine Reflexion über vier Verschiebungen, die zusammen eine andere Arbeitsweise ergeben: Die IDE wird optional. Der Browser kommt zu Claude. Prompts werden zu Skills. Und Claude nutzt sich selbst als Gedächtnis. Vier Thesen darüber, was passiert, wenn ein Werkzeug zur Umgebung wird.
These 1 – Die IDE wird optional
Jahrelang war die IDE das Zentrum. Alles lief über sie: Code schreiben, debuggen, navigieren, refactoren, Git-Operationen. Die IDE war nicht nur ein Werkzeug – sie war die Arbeitsumgebung. Der Ort, an dem Software entsteht. Wer die IDE nicht beherrschte, arbeitete langsamer. Also lernte man Shortcuts, konfigurierte Plugins, optimierte Layouts. Man investierte Stunden in die Konfiguration von Keybindings, Color Schemes, Code Inspections. Die IDE war die Verlängerung des eigenen Denkens.
Heute ist mein Hauptwerkzeug iTerm mit Claude Code. PyCharm öffne ich kaum noch, VS Code gar nicht mehr. Sublime Text nutze ich für schnelle Dateieinsicht ohne Kontext-Overhead. Fork für Git-Visualisierung und Merge-Konflikte. Das sind Ausnahmen, nicht die Regel.
Warum das passiert ist: Die IDE ist click-basiert. Claude Code ist konversationsbasiert. Für viele Workflows – Refactoring, Code-Analyse, Dateioperationen, Projektstruktur-Änderungen – wurde die IDE zum Umweg. "Öffne Datei X, navigiere zu Zeile Y, ändere Z" versus "Ändere Z in der Funktion, die für Y zuständig ist." Der zweite Weg ist nicht nur kürzer, sondern auch kontextreicher. Claude versteht die Absicht, nicht nur die Zeile.
Der eigentliche Produktivitätsgewinn liegt aber woanders: mehrere Instanzen parallel. Nicht eine Claude Code Session, sondern mindestens zwei – oft mehr. Zwei Szenarien:
Parallele Tasks im selben Projekt. Eine Instanz arbeitet an Feature A, eine andere reviewed Feature B. Wie manuell gesteuerte Subagenten – jede Instanz hat ihren eigenen Kontext, ihre eigene Aufgabe. Das ist etwas, was eine IDE nicht kann: echte Parallelität ohne Context-Switch.
Mehrere Projekte gleichzeitig. Blog-Artikel in einem Terminal, Code-Projekt in einem anderen, Dokumentation in einem dritten. Jede Instanz behält ihren Zustand. Kein Tab-Switching, kein Neuladen, kein "Wo war ich nochmal?"
Das Terminal wird zur Kommandozentrale. Nicht weil IDEs schlecht sind – sie werden nicht sterben. Für komplexe Merge-Konflikte greife ich nach wie vor zu Fork, weil die visuelle Darstellung von Drei-Wege-Merges im Terminal nicht ersetzbar ist. Und manchmal will ich einfach in eine Datei schauen, ohne eine Claude-Session zu starten – dafür reicht Sublime Text. Aber das sind bewusste Ausnahmen. Der Default hat sich umgekehrt: Früher war die IDE der Default und das Terminal die Ausnahme. Heute ist es andersherum.
These 2 – Claude bekommt direkten Browser-Zugang
Das alte Muster kennt jeder, der Frontend-Code schreibt oder APIs debuggt: Code schreiben, zum Browser wechseln, Ergebnis prüfen, Fehler manuell kopieren, zurück zu Claude, Kontext erklären. Bei jedem Debug-Zyklus ging Präzision verloren – weil ich in Worten beschreiben musste, was ich im Browser sah. "Da ist ein 404 auf der API-Route" ist weniger hilfreich als der tatsächliche Network-Request mit Headers, Timing und Response Body. Und je komplexer das Problem, desto mehr ging bei der manuellen Übersetzung verloren.
Im Januar-Artikel hatte ich das schlicht vergessen zu erwähnen – dabei war es damals schon täglich im Einsatz. Das neue Muster: Chrome DevTools MCP und Firefox DevTools MCP geben Claude direkten Zugang zum Browser. Console-Fehler, Network-Requests, DOM-Inspektion, Screenshots – Claude sieht, was im Browser passiert. Die Feedback-Schleife, die vorher offen war, ist geschlossen: Claude schreibt Code, der Browser rendert, Claude sieht das Ergebnis. Kein manuelles Zwischenschalten mehr, kein "Moment, ich schaue mal in die Console."
Konkrete Use Cases – ausschließlich Debugging und Analyse: - Console-Fehler direkt lesen und debuggen, statt Copy-Paste von Fehlermeldungen - Network-Requests inspizieren: API-Responses, Timing, Status Codes - DOM-Inspektion bei Layout-Problemen - Visual Regression durch Screenshots
Das ist kein Frontend-Entwicklungsframework. Es ist ein Debugging-Werkzeug. Claude schreibt nicht im Browser – Claude liest den Browser.
Parallel dazu bringt ContextMine interne Dokumentation zu Claude – lokale Codebases, Confluence-Exports, proprietäre APIs. Beide Tools folgen demselben Prinzip: Werkzeuge kommen zu Claude, nicht umgekehrt. Statt dass ich Kontext manuell sammle und in den Chat kopiere, holt sich Claude den Kontext selbst. Das reduziert nicht nur Arbeit, sondern verbessert die Qualität – weil Claude mehr Kontext sieht, als ich in Worten liefern würde.
★ Insight ──────────────────────────────────────────────────────────────────Die Verschiebung ist subtil aber fundamental: Von "ich beschreibe Claude, was ich sehe" zu "Claude sieht selbst." Das verändert nicht nur den Workflow, sondern die Art des Dialogs. Statt Symptome zu beschreiben, diskutiere ich mit Claude über Ursachen – weil wir dieselben Daten sehen.
────────────────────────────────────────────────────────────────────────────
These 3 – Skills ersetzen Prompts
Die 3x-Regel: Wenn ich etwas dreimal manuell prompte, wird ein Skill daraus. superpowers:writing-skills ist das Werkzeug dafür – ein Skill, der Skills schreibt. Das klingt meta, funktioniert aber: Ich beschreibe den wiederkehrenden Workflow, der Skill generiert die Struktur.
Das mayflow:update-Beispiel zeigt den natürlichen Entwicklungspfad. Es begann als einfaches Command – ein paar Zeilen, die CLAUDE.md aktualisieren. Dann wurde es ein globaler Skill unter ~/.claude/skills/, weil die Logik komplexer wurde. Heute ist es ein Skill in einem eigenen Plugin, massiv ausgebaut: Analyse von Conversation und Codebase, intelligente Verteilung von Insights auf verschiedene Dateien, Hierarchie-Management. Dieser Pfad – Command, globaler Skill, Plugin-Skill – war nicht geplant. Er hat sich durch Iteration ergeben.
Was hier passiert, ist ein konzeptueller Shift: von Prompt-Engineering zu Skill-Engineering. Ein Prompt ist flüchtig – er existiert in einer Konversation und geht mit ihr verloren. Ein Skill ist persistent, versioniert, iterierbar. Und anders als Commands liegt beim Startup nur die Beschreibung im Context, nicht der vollständige Inhalt. Commands werden komplett geladen, Skills nur mit ihrer Beschreibung – der volle Inhalt kommt erst bei Aufruf. Die erste Version ist selten perfekt. Nach zwei bis drei Durchläufen wird sie besser – weil die Praxis zeigt, was fehlt.
Skills sind keine Specs. Sie beschreiben keine Anforderungen, sondern Workflows. Aber sie teilen eine Erkenntnis mit Specs: Wer vorher kodifiziert, was passieren soll, arbeitet besser. Statt jedes Mal neu zu formulieren, was Claude tun soll, ist der Workflow einmal definiert und wird aufgerufen. Das ist keine Automatisierung im klassischen Sinne – es ist die Externalisierung von Arbeitsmustern.
Für Teams hat das eine zusätzliche Dimension: Skills in .claude/skills/ sind geteiltes Wissen. Wenn ein Entwickler einen Debugging-Workflow als Skill kodifiziert, profitiert das gesamte Team. Das ist etwas, was Prompts in Slack-Nachrichten nicht leisten – weil ein Skill nicht nur beschreibt, was zu tun ist, sondern es ausführbar macht.
★ Insight ──────────────────────────────────────────────────────────────────Der Shift von Prompt-Engineering zu Skill-Engineering verändert, was "Expertise" bedeutet. Es geht nicht mehr darum, den perfekten Prompt zu formulieren. Es geht darum, wiederkehrende Muster zu erkennen und sie so zu kodifizieren, dass sie wiederholbar, teilbar und verbesserbar werden. Das ist eine andere Kompetenz – näher an Software-Design als an Prompt-Crafting.
────────────────────────────────────────────────────────────────────────────
These 4 – Claude nutzt sich selbst als Gedächtnis
Cross-Session-Gedächtnis ist eines der größten offenen Probleme bei LLM-basierten Workflows. Jede neue Session startet bei null. Kein Kontext von gestern, keine Erinnerung an Entscheidungen von letzter Woche. Wer einmal drei Tage an einem komplexen Feature gearbeitet hat und dann in einer neuen Session den gesamten Kontext von vorne aufbauen musste, kennt die Frustration.
Die Entdeckung: Claude Code speichert jede Session als JSONL-Datei unter ~/.claude/projects/. Das ist kein beworbenes Feature – es ist ein Nebenprodukt der Session-Verwaltung. Aber es ist nutzbar. Jede Konversation wird als Folge von JSON-Objekten gespeichert, ein Objekt pro Message. Das JSONL-Format ist hier entscheidend: Jede Zeile ist ein eigenständiges JSON-Objekt. Claude kann Dateien partiell lesen – die ersten 100 Zeilen einer 10.000-Zeilen-Session reichen oft, um den Kontext zu verstehen. Diese Dateien können direkt an Claude übergeben werden: "Lies diese Session und finde die Architektur-Entscheidung von letzter Woche."
Use Cases: - Vergangene Entscheidungen rekonstruieren: "Was haben wir beim Datenbank-Schema entschieden?" - Architektur-Wahl nachvollziehen: "Welches Pattern haben wir für die API-Schicht gewählt und warum?" - Kontext zwischen Sessions überbrücken, statt alles neu zu erklären
Was das elegant macht: kein Setup, keine Konfiguration, kein zusätzliches Tool. Die Logs existieren bereits – man muss sie nur nutzen. Claude liest seine eigenen Spuren. Das System wird selbstreferentiell, ohne dass es so designt wurde.
Die ehrlichen Grenzen: Session-Mining erfordert manuelle Anweisung – Claude durchsucht Logs nicht automatisch. Ich muss aktiv sagen: "Lies die Session von letzter Woche." Die JSONL-Dateien können groß werden – eine mehrstündige Session erzeugt schnell tausende Zeilen. Und bei sehr großen Projekten mit hunderten Sessions wird die Navigation schwierig. Es ersetzt kein echtes Memory-MCP, das automatisch relevante Informationen indiziert und abrufbar macht. Es ist ein pragmatischer Workaround, kein vollwertiges Gedächtnis. Aber für die meisten meiner Projekte – wo ich die relevanten Sessions noch kenne und benennen kann – reicht es.
★ Insight ──────────────────────────────────────────────────────────────────Das Selbstreferentielle ist hier das Interessante: Ein System, das seine eigenen Output-Logs als Input nutzt. Keine externe Datenbank, kein konfiguriertes Memory – nur die natürlich entstehenden Artefakte der eigenen Arbeit. Das ist die einfachste Form von Gedächtnis: sich selbst lesen.
────────────────────────────────────────────────────────────────────────────
Das gemeinsame Prinzip: Erst denken, dann tun
Vier Thesen, ein Muster: Struktur vor Aktion.
Nicht alle vier Thesen stehen gleich nah an diesem Prinzip. These 1 und These 4 verbinden sich direkt mit der Idee, dass Denken vor Handeln kommen muss:
These 1 – IDE-freies Arbeiten zwingt zu klarerem Denken. Ohne grafische Oberfläche, die zum Klicken einlädt, muss ich formulieren, was ich will. Das ist langsamer als ein Doppelklick – aber es erzwingt, dass ich mein Ziel kenne, bevor ich handle. Spec-Driven Development formalisiert genau dieses Prinzip: erst spezifizieren, dann implementieren.
These 4 – Session-Mining zeigt, was in vergangenen Sessions wirklich wertvoll war. Und es sind fast nie Code-Fragmente. Es sind Entscheidungen: Warum dieses Pattern? Warum diese Library? Warum diese Architektur? Das, was man in alten Sessions sucht, ist fast immer die Spec-Ebene – die Begründung, nicht die Implementierung.
These 2 – Browser-Zugang folgt einem anderen Prinzip. Hier geht es nicht um Struktur vor Aktion, sondern um Kontext-Konvergenz: Werkzeuge kommen zu Claude, statt dass ich den Kontext manuell transportiere. Das ist wertvoll, aber es ist eine andere Art von Verschiebung.
These 3 – Skills sind keine Specs. Skills beschreiben Workflows, Specs beschreiben Anforderungen. Aber beide entstehen aus derselben Erkenntnis: Wer vorher denkt, arbeitet besser. Die Kodifizierung vor der Ausführung – ob als Skill oder als Spec – reduziert Fehler und erhöht die Konsistenz.
SDD als Haltung, nicht als Methodik. Nicht im Sinne von "installiere dieses Framework und folge diesen Schritten." Sondern im Sinne einer Grundfrage: "Habe ich definiert, was passieren soll, bevor es passiert?" Diese Frage durchzieht alle vier Thesen – mal direkt, mal als entferntes Echo. Es ist kein Framework, das man installiert. Es ist eine Denkweise, die sich einschleicht, wenn man lange genug mit einem System arbeitet, das Klarheit belohnt und Unklarheit bestraft.
Fazit
Das ist kein Setup mehr. Das ist eine Arbeitsweise.
Terminal statt IDE. Browser-Zugang statt Copy-Paste. Skills statt Prompts. Session-Logs statt Vergessen. Vier Verschiebungen, die zusammen etwas ergeben, das größer ist als die Summe der einzelnen Tools. Nicht weil die Tools spektakulär sind – sondern weil sie ein Muster verstärken: Struktur vor Aktion, Denken vor Handeln, Kodifizieren vor Ausführen. Der rote Faden ist nicht technisch. Er ist methodisch: Wer seine Werkzeuge nicht nur nutzt, sondern gestaltet, arbeitet anders.
Das ist mein Weg. Keine universelle Empfehlung, kein "So musst du arbeiten." Was ich beschreibe, hat sich aus meiner Praxis ergeben – iterativ, nicht geplant. Jemand mit einem anderen Stack, anderen Projekten, einem anderen Arbeitsstil wird andere Muster finden. Wer anders arbeitet, arbeitet nicht falsch. Aber wer anfängt, seine eigenen Muster zu beobachten und zu formalisieren, wird wahrscheinlich an ähnlichen Stellen landen: bei der Erkenntnis, dass Struktur vor Aktion kein Overhead ist, sondern die Voraussetzung dafür, dass Werkzeuge ihre Wirkung entfalten.
Die Exploration geht weiter. Die Werkzeuge reifen, die Arbeitsweisen vertiefen sich, und aus dem, was heute funktioniert, werden sich neue Muster ergeben. Welche das sein werden, zeigt die Praxis.
Dieser Artikel erschien ursprünglich auf dem Mayflower Blog.