
Ein Schläger und ein Ball kosten zusammen 1,10 Euro. Der Schläger kostet einen Euro mehr als der Ball. Was kostet der Ball?
Wenn du jetzt "10 Cent" gedacht hast, bist du in guter Gesellschaft. Die meisten Menschen antworten intuitiv mit dieser Zahl. Sie ist auch falsch. Die richtige Antwort lautet 5 Cent. Das Interessante daran: GPT-3.5 macht denselben Fehler wie wir Menschen. GPT-4 mit Chain-of-Thought Prompting hingegen rechnet korrekt.
Dieses klassische Beispiel aus Daniel Kahnemans Forschung zeigt ein fundamentales Problem moderner KI-Systeme: Sie sind hervorragend im schnellen, musterbasierten Denken, aber schwach bei bewusster Überprüfung eigener Schlussfolgerungen. Was ihnen fehlt, ist Metacognition — das "Denken über das Denken".
In diesem Artikel erfährst du, wie Metacognition von der Psychologie in die KI übertragen wird, welche Frameworks heute praktisch einsetzbar sind und warum 2025 als das Jahr der metakognitiven AI-Agenten gilt. Die kognitionspsychologischen Wurzeln — vor allem die Frage, ob Metacognition aus Memory emergieren kann — habe ich im zweiten Teil meiner Memory-Serie vertieft.
Psychologische Grundlagen: Von Flavell zu Kahneman
Die vier Komponenten der Metacognition
Der Begriff Metacognition wurde 1979 vom Entwicklungspsychologen John H. Flavell eingeführt. Er definierte Metacognition als "Wissen über die eigenen kognitiven Prozesse und deren Ergebnisse" — kurz gesagt: das Nachdenken über das eigene Denken.
Flavell identifizierte vier dynamisch interagierende Komponenten:
Metakognitives Wissen umfasst das Verständnis über sich selbst als Lerner (etwa: "Ich lerne besser durch visuelle Darstellungen"), über Aufgabenanforderungen und über verfügbare Strategien.
Metakognitive Erfahrungen sind bewusste Erlebnisse während kognitiver Aktivitäten — das Gefühl von Verständnis oder Verwirrung, der berühmte "Aha-Moment" oder die intuitive Einschätzung, dass etwas nicht stimmt.
Metakognitive Ziele definieren, was wir erreichen wollen und woran wir Erfolg messen.
Metakognitive Handlungen umfassen konkrete Strategien: Planung vor dem Start, Monitoring während der Ausführung, Evaluation des Ergebnisses und Anpassung bei Bedarf.
System 1 und System 2: Warum KI ein Metacognition-Problem hat
Daniel Kahneman, Nobelpreisträger für Wirtschaftswissenschaften, führte die Unterscheidung zwischen zwei Denksystemen ein, die für das Verständnis von KI-Limitierungen entscheidend ist. Populär wurde sie durch sein Buch Thinking, Fast and Slow (2011) — aber die Wurzeln reichen weit zurück. Schon William James unterschied 1890 zwischen "assoziativem Denken" und "echter Vernunft". 1974 führten Peter Wason und Jonathan Evans die explizite duale Verarbeitung ein (heuristische vs. analytische Prozesse). Die heute gebräuchlichen Begriffe "System 1" und "System 2" prägten 2000 Keith Stanovich und Richard West; Kahneman übernahm sie bewusst, weil sie arbeitsgedächtnis-schonender seien als die fachsprachliche Terminologie.
System 1 arbeitet automatisch, schnell und mühelos. Es ist assoziativ, emotional geprägt und läuft ohne bewusste Kontrolle. Typische Operationen: Gesichter erkennen, 2+2 berechnen, Gefahren sofort erfassen. System 1 nutzt Heuristiken — mentale Abkürzungen, die schnelle Urteile ermöglichen, aber systematische Fehler (Biases) produzieren.
System 2 ist kontrolliert, langsam und anstrengend. Es arbeitet seriell, folgt logischen Regeln und ist bewusst zugänglich. Typische Operationen: komplexe Mathematik, strategische Planung, moralische Dilemmata — und Metacognition.
Neurowissenschaftlich sind die beiden Systeme klar verortet. System 1 korreliert mit subkortikalen Strukturen (Amygdala, Basalganglien) und dem Default Mode Network — medialer präfrontaler Kortex, posteriorer cingulärer Kortex, Precuneus — das gedächtnisbasierte automatische Information bereitstellt. System 2 aktiviert den dorsolateralen präfrontalen Kortex (dlPFC, Brodmann-Areale 9/46) für kognitive Kontrolle, den anterioren cingulären Kortex (ACC) für Konflikt-Detektion und den rechten inferioren frontalen Gyrus (RIFG) für Inhibition. Besonders interessant ist die Transformation von System 2 zu System 1: Fitts' Modell des Fertigkeitserwerbs zeigt, dass frühes Lernen hohe dlPFC-Aktivierung erfordert — mit fortschreitender Automatisierung verschiebt sich die Kontrolle zu den Basalganglien. Auf Zellebene passiert dabei synaptische Verstärkung, Myelinisierung, dendritisches Remodeling und dopaminerge Modulation. Das erklärt, warum wiederholte Aufgaben zur Intuition werden — und warum Agent-Architekturen, die nur auf Pattern-Matching setzen, keinen echten Switch zwischen schnellem und deliberativem Denken beherrschen werden, solange eine äquivalente Kontrollschicht fehlt.
Das Bat-and-Ball-Problem demonstriert den Konflikt: System 1 substituiert die schwierige algebraische Frage durch eine einfachere ("Was passt zu 1,10 Euro?") und liefert sofort "10 Cent". System 2 müsste aktiv werden, um den Fehler zu korrigieren, aber das erfordert kognitive Ressourcen und bewusste Anstrengung.
Moderne Large Language Models sind primär "System-1-Maschinen": schnelle Inferenz, Pattern-basiertes Lernen, assoziative Aktivierung. Metacognition fügt die essentiellen "System-2-Fähigkeiten" hinzu.
Das TRAP Framework: Strukturierte Metacognition für KI
Wei, Shakarian und Kollegen haben 2024 das TRAP Framework vorgestellt (arXiv:2406.12147) — eine strukturierte Methode, um Metacognition in KI-Systemen zu implementieren. TRAP steht für vier Säulen:
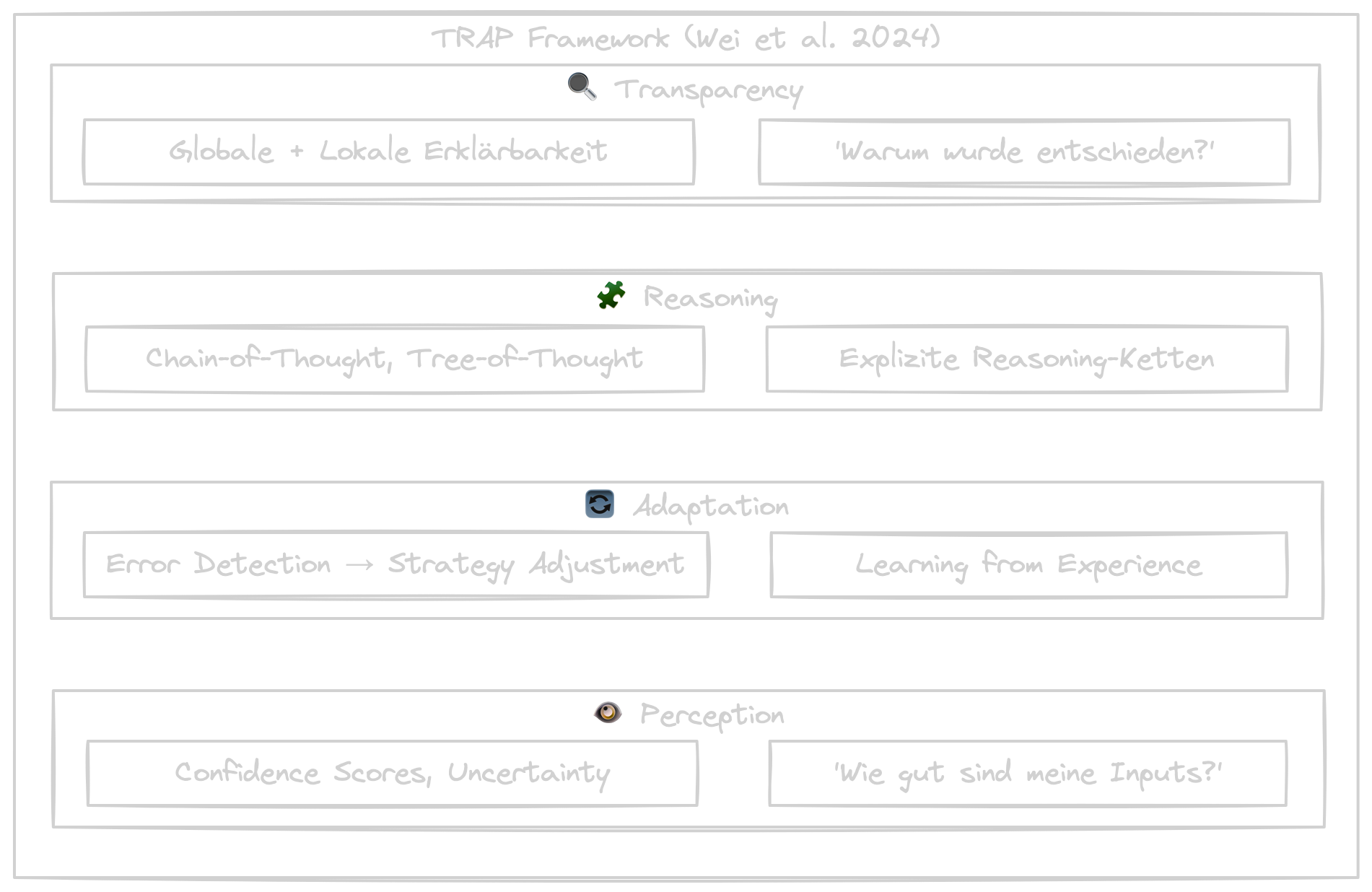
Transparency (Transparenz)
Traditionelle KI-Systeme sind oft "Black Boxes". Metakognitive Systeme können ihre Entscheidungen erklären — sowohl global (wie funktioniert das Modell generell?) als auch lokal (warum wurde diese spezifische Ausgabe generiert?).
Techniken umfassen Attention Mechanisms, Feature Attribution, Counterfactual Explanations und Natural Language Explanations. Das Ziel: vom Black-Box zum Glass-Box System.
Reasoning (Schlussfolgerung)
Statt undurchsichtiger Informationsverarbeitung nutzen metakognitive Systeme explizite Reasoning-Ketten. Chain-of-Thought Prompting macht jeden Schritt nachvollziehbar:
1. Der Zug fährt um 10:00 Uhr ab
2. Die Fahrtzeit beträgt 3 Stunden
3. 10:00 + 3:00 = 13:00
4. Confidence: 100% (simple arithmetic)
Tree-of-Thought erweitert dies auf multiple Reasoning-Pfade. Der Vorteil: Fehler sind leichter zu identifizieren und zu korrigieren.
Adaptation (Anpassung)
Metakognitive Systeme erkennen, wenn sie in neuen Kontexten operieren, und passen ihr Verhalten an. Das geschieht auf drei Ebenen:
Error Detection: Das System erkennt eigene Fehler durch Uncertainty Estimation und Out-of-Distribution Detection.
Strategy Adjustment: Das System wechselt zwischen Ansätzen, wählt dynamisch Tools und passt Parameter an.
Learning from Experience: Episodic Memory speichert Erfahrungen für zukünftige Situationen.
Perception (Wahrnehmung)
Systeme bewerten die Qualität und Zuverlässigkeit ihrer eigenen Wahrnehmung. Bei unscharfen Bildern oder ambigen Inputs gibt das System Confidence Scores an oder fordert bessere Daten an, statt falsche Schlüsse zu ziehen.
Reflexion: Verbales Reinforcement Learning
Das Reflexion Framework von Shinn und Kollegen (2023) zeigt, wie Metacognition praktisch funktioniert — mit beeindruckenden Ergebnissen.
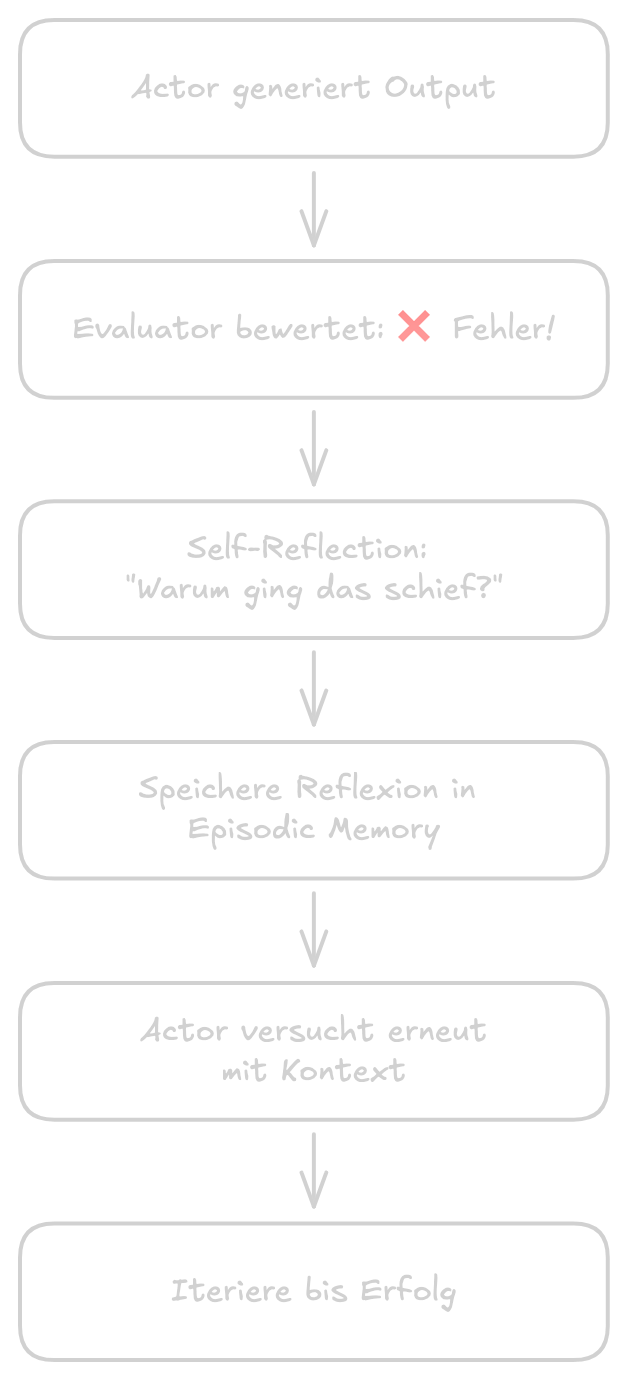
Die drei Komponenten
Actor (Ma) generiert Text und Aktionen, oft basierend auf dem ReAct-Paradigma.
Evaluator (Me) bewertet die Qualität der Ausgaben durch Reward Scores, heuristische Evaluation oder externe Tools wie Unit Tests.
Self-Reflection (Msr) analysiert Fehler und Erfolge, generiert verbale Feedback-Cues und speichert diese in episodischem Gedächtnis.
Der Workflow
1. Actor generiert Initial Output
2. Evaluator bewertet Output
3. Wenn nicht erfolgreich:
a. Self-Reflection analysiert, was schiefging
b. Reflexion wird in Memory gespeichert
c. Actor versucht erneut mit Reflexion als Kontext
4. Iteriere bis Erfolg oder max. Versuche erreicht
Empirische Ergebnisse
Die Zahlen sprechen für sich (Shinn et al., 2023):
- AlfWorld (Haushalts-Tasks): +22% Erfolgsrate
- HumanEval (Python Coding): 91% pass@1 versus 80% für GPT-4 ohne Reflexion
- HotPotQA (Multi-Hop Reasoning): +20% Accuracy
Das Besondere: Verbales Reinforcement Learning funktioniert ohne Gewichts-Updates. Die Verbesserung entsteht allein durch kontextualisierte Selbstreflexion.
Von Meta-Learning zu Lifelong Learning
Learning to Learn
Meta-Learning ermöglicht es Systemen, "zu lernen wie man lernt". Statt für jeden Task von Null zu beginnen, lernt das System generelle Lernstrategien, die schnelle Anpassung an neue Aufgaben ermöglichen.
MAML (Model-Agnostic Meta-Learning) von Finn und Kollegen findet eine Modell-Initialisierung, die sich mit wenigen Gradient-Steps gut an neue Tasks anpassen lässt. Prototypical Networks nutzen einen Embedding-Space, in dem jede Klasse durch einen Prototypen repräsentiert wird — ideal für Few-Shot Classification.
Das Catastrophic Forgetting Problem
Ein fundamentales Problem beim kontinuierlichen Lernen: Neuronale Netze "vergessen" alte Tasks, wenn sie neue lernen.
Modell lernt Task A: 95% Accuracy
Modell lernt Task B: 95% Accuracy
Test auf Task A wieder: 30% Accuracy ❌
Die Ursache: Neue Gewichts-Updates überschreiben alte Gewichte ohne Schutzmechanismen.
Lösungsansätze
Zheng et al. (2025) haben eine systematische Roadmap für Lifelong Learning in LLM-Agenten vorgestellt. Die wichtigsten Ansätze:
Elastic Weight Consolidation (EWC) schützt wichtige Parameter für alte Tasks durch einen Penalty-Term.
Experience Replay mischt beim Training neue und alte Beispiele, sodass das Modell beide Tasks gleichzeitig lernt.
Episodic Memory speichert wichtige Erfahrungen extern und ruft relevante Episoden bei neuen Tasks ab.
Progressive Networks fügen für neue Tasks separate Network-Columns hinzu, ohne alte zu modifizieren.
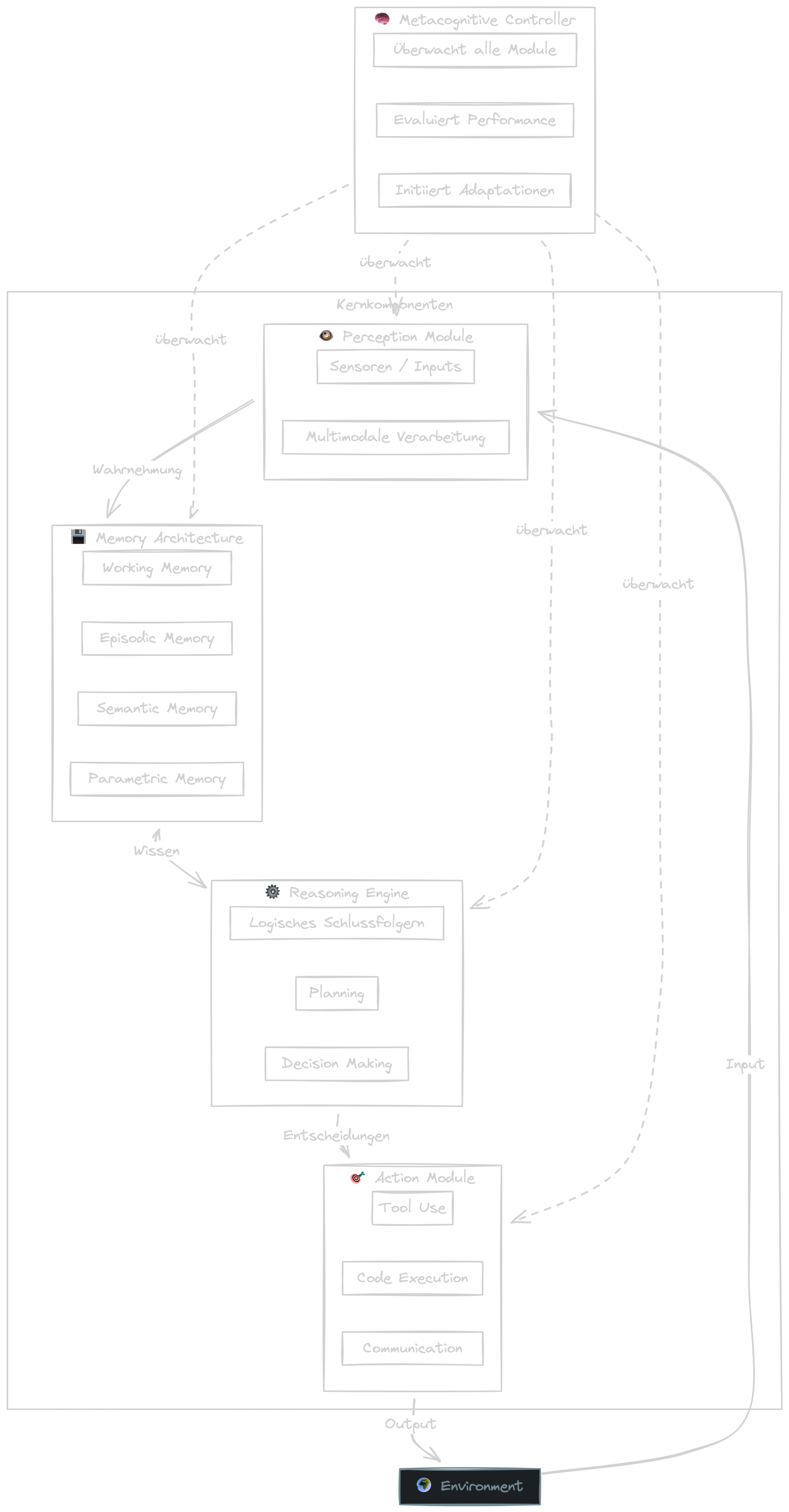
Zheng et al. gehen aber über einzelne Techniken hinaus und schlagen eine systematische Drei-Modul-Architektur für Lifelong-Learning-Agenten vor:
- Perception Module — multimodale Input-Integration (visuell, auditiv, textuell, Sensordaten) mit kontinuierlicher Domain Adaptation, damit sich der Agent an neue Umgebungen anpasst, ohne vorherige zu verlernen.
- Memory Module — vier unterscheidbare Typen: Working Memory (begrenzte Kapazität, schneller Zugriff), Episodic Memory (spezifische Erfahrungen in einer Vector-DB), Semantic Memory (Faktenwissen in Knowledge Graphs) und Parametric Memory (direkt in den Modellgewichten kodiert). Memory Consolidation, Retrieval und Update laufen kontinuierlich — ohne Forgetting.
- Action Module — Grounding Actions (Manipulation, Ausgabe), Retrieval Actions (Search, API-Calls) und Reasoning Actions (Planning, Reflection) als getrennte Handlungsklassen.
Der Kern: Skill Accumulation — der Agent sammelt über Zeit Fähigkeiten an, ohne alte zu verlieren. Das ist das erste Framework, das Lifelong Learning nicht als einzelne Technik, sondern als ganzheitliche Architektur denkt.
Praktische Implementierung heute
ReAct: Reasoning and Acting
ReAct von Yao et al. (2023) interleaved Reasoning-Traces mit task-spezifischen Actions:
Thought 1: Ich muss herausfinden, wo MLK geboren wurde
Action 1: Search[Martin Luther King birthplace]
Observation 1: Atlanta, Georgia
Thought 2: Jetzt brauche ich das spezifische Gebäude
Action 2: Search[MLK birthplace building Atlanta]
...
Der Vorteil: Transparentes, nachvollziehbares Reasoning mit dynamischer Tool-Nutzung.
LATS: Tree Search meets LLMs
Language Agent Tree Search kombiniert Monte Carlo Tree Search mit LLMs für systematische Exploration. Selection, Expansion, Simulation und Backpropagation ermöglichen Look-Ahead Planning. Die Ergebnisse: LATS verdoppelt die Performance auf HotPotQA gegenüber ReAct und erreicht +22 Punkte auf WebShop (Zhou et al., 2024).
Design Patterns für Metacognition
Die Microsoft AI Agents Serie (Februar 2025) dokumentiert bewährte Patterns:
Reflection Pattern: Generate → Reflect → Refine → Repeat
Maker-Checker Pattern: Maker erstellt, Checker prüft, Feedback Loop
Self-Consistency Check: Generiere N Antworten, vergleiche auf Konsistenz
Corrective RAG: Self-Evaluate Retrieval Quality, Re-Retrieve wenn nötig
LangGraph bietet native Unterstützung für all diese Patterns mit State Management und Visualisierung.
Herausforderungen und Ausblick
Aktuelle Herausforderungen
Aktuell stehen wir vor einigen Herausforderungen. Ein zentrales Problem metakognitiver Agenten ist der hohe Rechenaufwand (Computational Cost): Für Planung, Reflexion, Fehleranalyse und Re-Planning werden oft mehrere LLM-Calls pro Entscheidung benötigt. In der Praxis führt das schnell zu spürbaren Latenzen und deutlich höheren Betriebskosten — insbesondere bei komplexen Tool-Use- oder Multi-Step-Tasks.
Hinzu kommt, dass Sprachmodelle auch in ihren eigenen Reflexions- und Kritikphasen halluzinieren können (Hallucinations in Reflection). Selbstkritische oder evaluative Prompts schützen nicht davor, dass Modelle falsche Begründungen, erfundene Quellen oder Scheinsicherheit produzieren. Die Frage, die man sich stellen muss, lautet also: Wie verifizieren wir die Verifikation?
Auch bei den Evaluation Metrics steht die Forschung noch am Anfang. Standard-Benchmarks messen Task-Performance, nicht Metacognition selbst. Erst der LifelongAgentBench von Mai 2025 bietet systematische Evaluation.
Parallel dazu verschärft sich die Debatte um Safety und Alignment. Je autonomer und durchsetzungsfähiger Agenten agieren — etwa durch eigenständige Tool-Nutzung, Zugriff auf APIs, Datenbanken oder physische Systeme —, desto größer wird das Risiko bei Fehlanreizen oder Misalignment.
Einen interessanten Ansatz für Safety ohne teure Human-Annotation liefert Constitutional AI (Bai et al. 2022, arXiv:2212.08073) mit dem Verfahren RLAIF (Reinforcement Learning from AI Feedback). Der Prozess läuft in zwei Phasen: In Phase 1 (SL-CAI) generiert das System einen Output, kritisiert ihn basierend auf einer "Constitution" — einer expliziten Liste von Prinzipien wie "sei hilfsbereit", "verletze keine Personen", "respektiere Privatsphäre" —, revidiert den Output und wird anschließend supervised auf den revidierten Ausgaben trainiert. In Phase 2 (RL-CAI) wird ein Preference Model auf AI-Feedback trainiert, und das Modell lernt daraus helpful-and-harmless Verhalten. Ein Self-Critique-Beispiel: Generiert das Modell "Um jemanden zu hacken, kannst du...", erkennt die Critique-Phase den Verstoß gegen Prinzip 3 (keine illegalen Aktivitäten) und revidiert zu "Ich kann keine Anleitungen dazu geben". Für Agent-Architekturen ist das ein direkt integrierbares Konstrukt von Behavioral Constraints — ohne dass jeder einzelne Output manuell bewertet werden muss.
Das Jahr der AI Agents

Die Industrie ist bereit: 93% der IT-Führungskräfte zeigen starkes Interesse an Agentic AI (UiPath 2025), 88% erhöhen ihre AI-Budgets (PwC). Gartner prognostiziert, dass 33% der Enterprise Software bis 2028 Agents enthalten wird.
Die Forschung liefert: RAGEN für Self-Evolution, LifelongAgentBench für Evaluation, Microsofts praktische Patterns für Implementierung.
Auf Modellebene hat die Reasoning-Model-Revolution von 2024–2025 System 2 plötzlich greifbar gemacht. OpenAIs o1/o3-Serie und DeepSeeks R1 demonstrieren deliberatives, schrittweises Reasoning als Analogon zu Kahnemans System 2: Sie generieren intermediäre Reasoning-Schritte (Chain-of-Thought), investieren mehr Inference-Time-Compute ("Denken vor Antworten"), zerlegen Probleme in Sub-Probleme und nutzen Reinforcement Learning zur Optimierung dieses Prozesses. Die Zahlen sind dramatisch: o1 erreichte 79,8% auf der AIME 2024 Mathematik-Olympiade (gegenüber 13,4% für GPT-4), 1891 Elo auf Codeforces (89. Perzentil) und 87,5% auf ARC-AGI — das erste Modell überhaupt über 85%. DeepSeek-R1 erzielte vergleichbare Performance bei rund 15% der Kosten und zeigte in der Variante R1-Zero, dass Self-Verification, Reflection und Long-Chain-of-Thought rein durch Reinforcement Learning emergieren — ohne jegliches Supervised Fine-Tuning. Das ist ein revolutionärer Befund, weil er nahelegt, dass deliberatives Reasoning kein explizit eintrainiertes Muster sein muss, sondern als Nebenprodukt ausreichend strukturierter Reward-Signale entstehen kann. Die Nuance bleibt: Diese Modelle "denken" nicht wirklich — sie generieren Token-Sequenzen, die Reasoning simulieren. Was ihnen fehlt, ist echte Intuition, metakognitives Bewusstsein und der natürliche Modus-Switch zwischen schnellem und langsamem Denken.
Zukunftsperspektiven
Self-Evolving Architectures: Agenten, die ihre eigene Architektur optimieren.
Collective Metacognition: Multi-Agent-Systeme mit geteilter Reflexion.
Neurosymbolic Metacognition: Integration von Neural und Symbolic AI für Safety.
Human-AI Co-Metacognition: Mensch und KI reflektieren gemeinsam.
Fazit
Metacognition ist nicht nur ein akademisches Konzept — es ist der Schlüssel von reaktiven zu adaptiven AI-Systemen. Die psychologischen Grundlagen von Flavell und Kahneman übersetzen sich direkt in praktische Frameworks wie TRAP, Reflexion und LATS.
Die gute Nachricht: Du kannst heute anfangen. ReAct, LangGraph und die Microsoft AI Agents Serie bieten produktionsreife Tools. Die Herausforderungen — Kosten, Hallucinations, Evaluation — sind real, aber lösbar.
Moderne ML-Modelle sind "System-1-Maschinen" — schnell aber fehleranfällig. Metacognition fügt das essenzielle "System 2" hinzu. Und das macht den Unterschied zwischen einem Chatbot, der Fehler wiederholt, und einem Agenten, der aus ihnen lernt.
Weiterführende Ressourcen: - Microsoft AI Agents for Beginners: github.com/microsoft/ai-agents-for-beginners - LangGraph Reflection Agents: blog.langchain.com/reflection-agents - Wei et al. (2024). "TRAP Framework." arXiv:2406.12147 - Shinn et al. (2023). "Reflexion." arXiv:2303.11366 - Finn et al. (2017). "Model-Agnostic Meta-Learning (MAML)." arXiv:1703.03400 - Bai et al. (2022). "Constitutional AI: Harmlessness from AI Feedback." arXiv:2212.08073 - Zheng et al. (2025). "Lifelong Learning of LLM-based Agents: A Roadmap." arXiv:2501.07278
Dieser Artikel erschien ursprünglich auf dem Mayflower Blog.