
A bat and a ball cost $1.10 together. The bat costs $1.00 more than the ball. How much does the ball cost?
If you thought "10 cents," you're not alone. Most people give that answer intuitively. It's also wrong. The correct answer is 5 cents. Here's what makes this interesting: GPT-3.5 makes the exact same mistake we humans do. GPT-4 with chain-of-thought prompting, however, gets it right.
This classic example from Daniel Kahneman's research reveals a fundamental problem of modern AI systems: they excel at fast, pattern-based thinking but are weak at consciously verifying their own conclusions. What they lack is metacognition — the ability to "think about thinking."
In this article, I'll show you how metacognition is being transferred from psychology to AI, which frameworks are practically usable today, and why 2025 is shaping up to be the year of metacognitive AI agents. The cognitive-psychology roots — especially the question whether metacognition can emerge from memory — I explored in the second part of my memory series.
Psychological Foundations: From Flavell to Kahneman
The Four Components of Metacognition
The term metacognition was introduced in 1979 by developmental psychologist John H. Flavell. He defined metacognition as "knowledge concerning one's own cognitive processes and their outcomes" — in short: thinking about your own thinking.
Flavell identified four dynamically interacting components:
Metacognitive knowledge encompasses understanding of yourself as a learner (for example: "I learn better through visual representations"), of task requirements, and of available strategies.
Metacognitive experiences are conscious experiences during cognitive activities — the feeling of understanding or confusion, the famous "aha moment," or the intuitive sense that something is off.
Metacognitive goals define what we want to achieve and how we measure success.
Metacognitive actions comprise concrete strategies: planning before starting, monitoring during execution, evaluating results, and adjusting when needed.
System 1 and System 2: Why AI Has a Metacognition Problem
Daniel Kahneman, Nobel laureate in economics, introduced the distinction between two thinking systems that is crucial for understanding AI limitations. It was popularized by his book Thinking, Fast and Slow (2011) — but the roots go much deeper. William James already distinguished in 1890 between "associative thinking" and "true reasoning." In 1974, Peter Wason and Jonathan Evans introduced explicit dual processing (heuristic vs. analytical processes). The terms "System 1" and "System 2" we use today were coined in 2000 by Keith Stanovich and Richard West; Kahneman adopted them deliberately because they were easier on working memory than technical terminology.
System 1 operates automatically, quickly, and effortlessly. It's associative, emotionally driven, and runs without conscious control. Typical operations: recognizing faces, calculating 2+2, instantly assessing danger. System 1 uses heuristics — mental shortcuts that enable fast judgments but produce systematic errors (biases).
System 2 is controlled, slow, and effortful. It works serially, follows logical rules, and is consciously accessible. Typical operations: complex mathematics, strategic planning, moral dilemmas — and metacognition.
Neuroscientifically, the two systems are clearly localized. System 1 correlates with subcortical structures (amygdala, basal ganglia) and the Default Mode Network — medial prefrontal cortex, posterior cingulate cortex, precuneus — which provides memory-based automatic information. System 2 activates the dorsolateral prefrontal cortex (dlPFC, Brodmann areas 9/46) for cognitive control, the anterior cingulate cortex (ACC) for conflict detection, and the right inferior frontal gyrus (RIFG) for inhibition. Particularly interesting is the transformation from System 2 to System 1: Fitts' model of skill acquisition shows that early learning requires high dlPFC activation — with progressive automation, control shifts to the basal ganglia. At the cellular level, this involves synaptic strengthening, myelination, dendritic remodeling, and dopaminergic modulation. That explains why repeated tasks become intuition — and why agent architectures based purely on pattern matching will never master a real switch between fast and deliberative thinking without an equivalent control layer.
The bat-and-ball problem demonstrates the conflict: System 1 substitutes the difficult algebraic question with a simpler one ("What goes with $1.10?") and instantly delivers "10 cents." System 2 would need to actively intervene to catch the error, but that requires cognitive resources and conscious effort.
Modern large language models are primarily "System 1 machines": fast inference, pattern-based learning, associative activation. Metacognition adds the essential "System 2" capabilities.
The TRAP Framework: Structured Metacognition for AI
Wei, Shakarian, and colleagues introduced the TRAP Framework in 2024 (arXiv:2406.12147) — a structured method for implementing metacognition in AI systems. TRAP stands for four pillars:
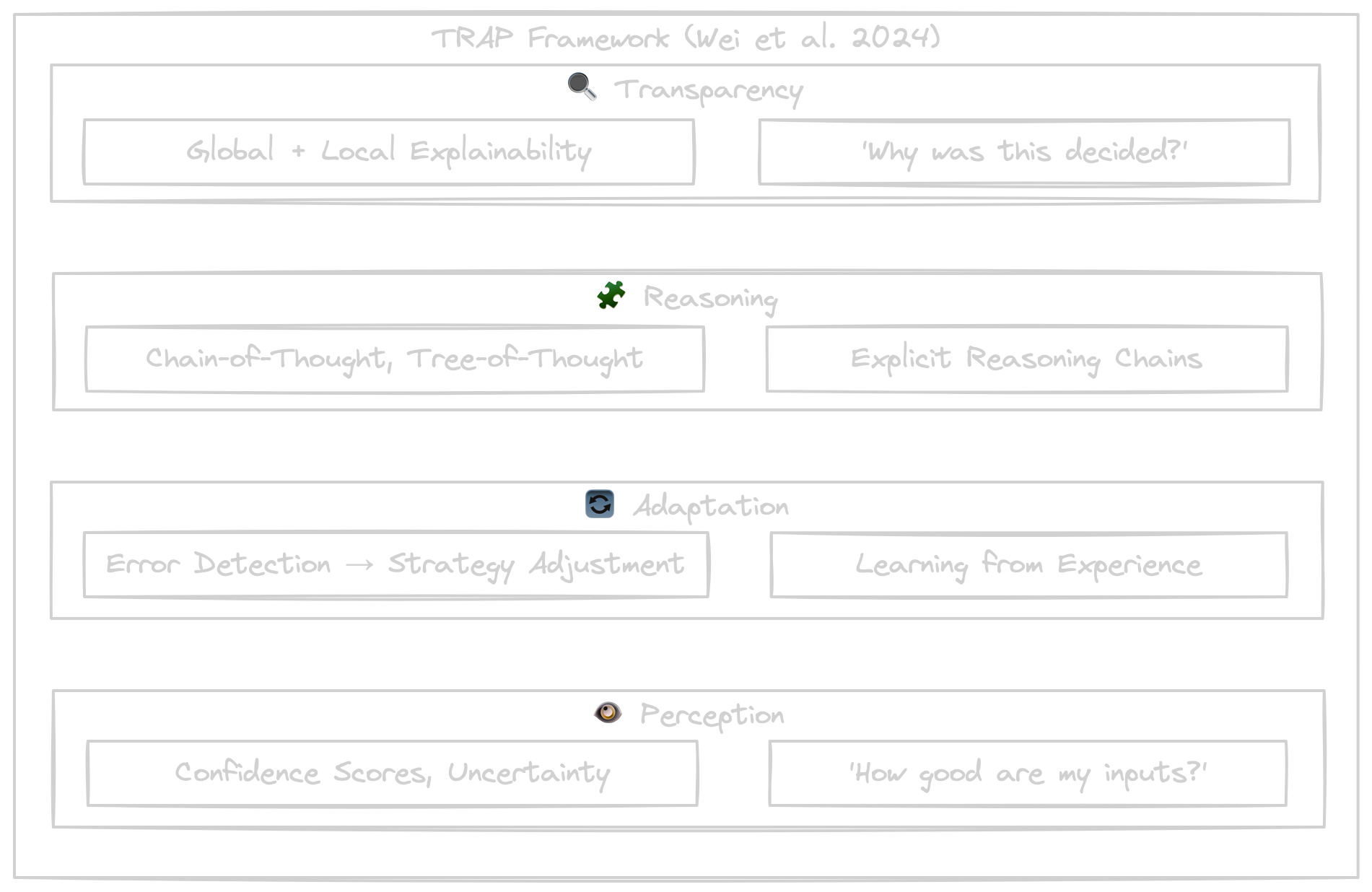
Transparency
Traditional AI systems are often "black boxes." Metacognitive systems can explain their decisions — both globally (how does the model work in general?) and locally (why was this specific output generated?).
Techniques include attention mechanisms, feature attribution, counterfactual explanations, and natural language explanations. The goal: from black-box to glass-box system.
Reasoning
Instead of opaque information processing, metacognitive systems use explicit reasoning chains. Chain-of-thought prompting makes every step traceable:
1. The train departs at 10:00
2. Travel time is 3 hours
3. 10:00 + 3:00 = 13:00
4. Confidence: 100% (simple arithmetic)
Tree-of-thought extends this to multiple reasoning paths. The advantage: errors are easier to identify and correct.
Adaptation
Metacognitive systems recognize when they're operating in new contexts and adjust their behavior accordingly. This happens at three levels:
Error Detection: The system recognizes its own errors through uncertainty estimation and out-of-distribution detection.
Strategy Adjustment: The system switches between approaches, dynamically selects tools, and adjusts parameters.
Learning from Experience: Episodic memory stores experiences for future situations.
Perception
Systems assess the quality and reliability of their own perception. With blurry images or ambiguous inputs, the system provides confidence scores or requests better data rather than drawing false conclusions.
Reflexion: Verbal Reinforcement Learning
The Reflexion Framework by Shinn and colleagues (2023) shows how metacognition works in practice — with impressive results.
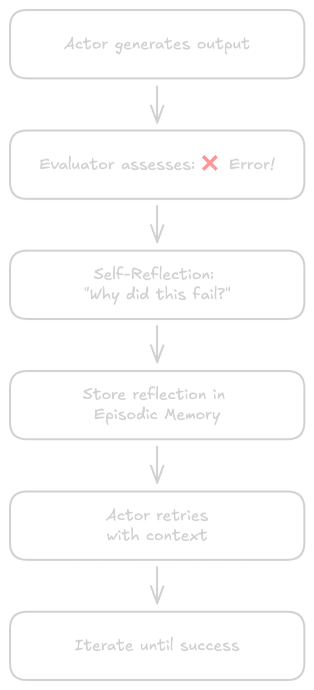
The Three Components
Actor (Ma) generates text and actions, often based on the ReAct paradigm.
Evaluator (Me) assesses output quality through reward scores, heuristic evaluation, or external tools like unit tests.
Self-Reflection (Msr) analyzes failures and successes, generates verbal feedback cues, and stores them in episodic memory.
The Workflow
1. Actor generates initial output
2. Evaluator assesses output
3. If not successful:
a. Self-Reflection analyzes what went wrong
b. Reflection is stored in memory
c. Actor tries again with reflection as context
4. Iterate until success or max attempts reached
Empirical Results
The numbers speak for themselves (Shinn et al., 2023):
- AlfWorld (household tasks): +22% success rate
- HumanEval (Python coding): 91% pass@1 versus 80% for GPT-4 without reflection
- HotPotQA (multi-hop reasoning): +20% accuracy
What's remarkable: verbal reinforcement learning works without weight updates. The improvement comes purely from contextualized self-reflection.
From Meta-Learning to Lifelong Learning
Learning to Learn
Meta-learning enables systems to "learn how to learn." Instead of starting from scratch for every task, the system learns general learning strategies that enable rapid adaptation to new tasks.
MAML (Model-Agnostic Meta-Learning) by Finn and colleagues finds a model initialization that adapts well to new tasks with just a few gradient steps. Prototypical Networks use an embedding space where each class is represented by a prototype — ideal for few-shot classification.
The Catastrophic Forgetting Problem
A fundamental problem in continuous learning: neural networks "forget" old tasks when learning new ones.
Model learns Task A: 95% accuracy
Model learns Task B: 95% accuracy
Test on Task A again: 30% accuracy ❌
The cause: new weight updates overwrite old weights without protective mechanisms.
Solutions
Zheng et al. (2025) published a systematic roadmap for lifelong learning in LLM agents. The key approaches:
Elastic Weight Consolidation (EWC) protects important parameters for old tasks through a penalty term.
Experience Replay mixes new and old examples during training so the model learns both tasks simultaneously.
Episodic Memory stores important experiences externally and retrieves relevant episodes for new tasks.
Progressive Networks add separate network columns for new tasks without modifying old ones.
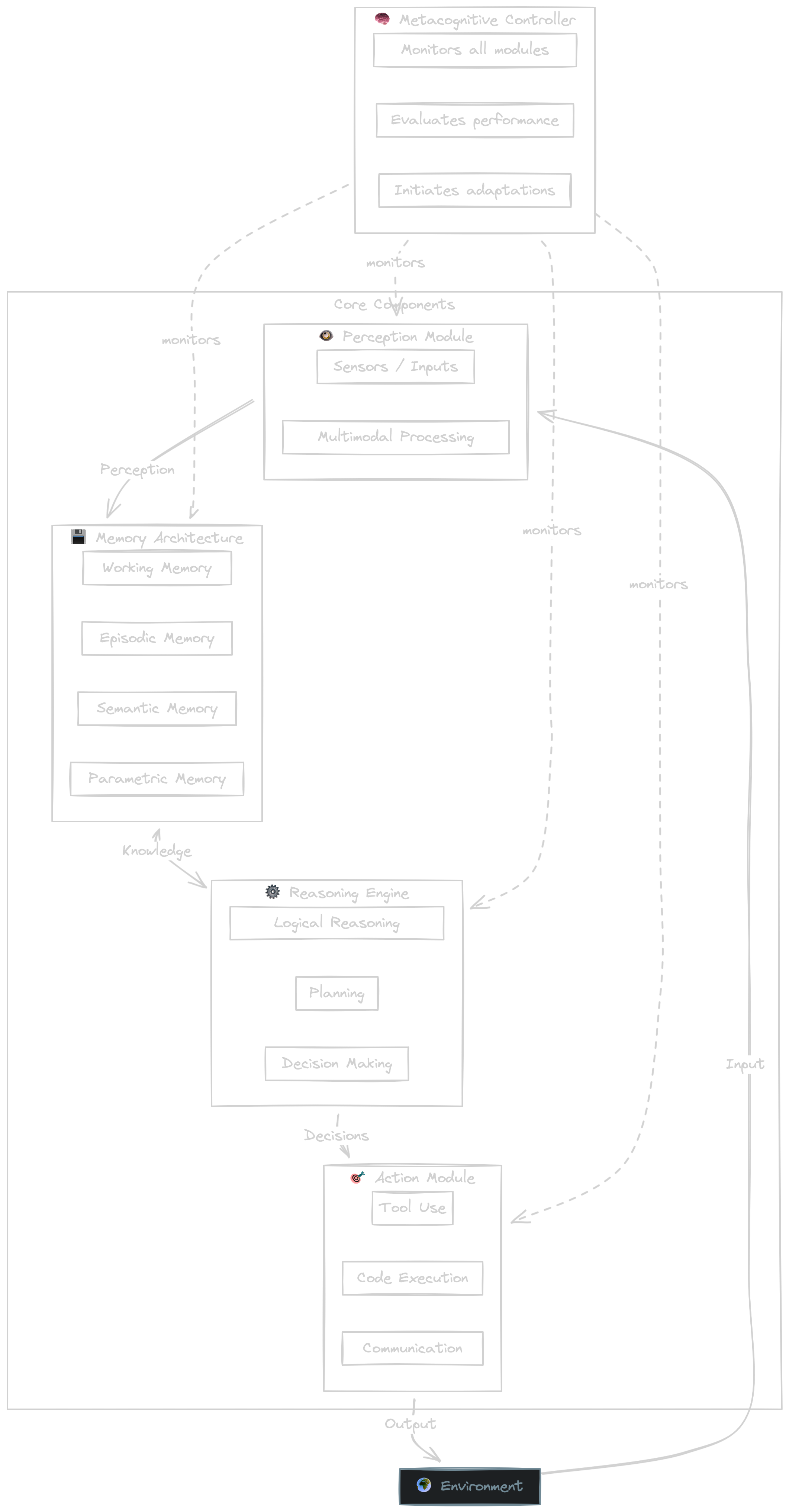
But Zheng et al. go beyond individual techniques and propose a systematic three-module architecture for lifelong-learning agents:
- Perception Module — multimodal input integration (visual, auditory, textual, sensor data) with continuous domain adaptation, so the agent adapts to new environments without unlearning previous ones.
- Memory Module — four distinguishable types: Working Memory (limited capacity, fast access), Episodic Memory (specific experiences in a vector DB), Semantic Memory (factual knowledge in knowledge graphs), and Parametric Memory (encoded directly in the model weights). Memory consolidation, retrieval, and update run continuously — without forgetting.
- Action Module — Grounding Actions (manipulation, output), Retrieval Actions (search, API calls), and Reasoning Actions (planning, reflection) as separate action classes.
The core: Skill Accumulation — the agent accumulates capabilities over time without losing old ones. This is the first framework that treats lifelong learning not as a single technique but as a holistic architecture.
Practical Implementation Today
ReAct: Reasoning and Acting
ReAct by Yao et al. (2023) interleaves reasoning traces with task-specific actions:
Thought 1: I need to find where MLK was born
Action 1: Search[Martin Luther King birthplace]
Observation 1: Atlanta, Georgia
Thought 2: Now I need the specific building
Action 2: Search[MLK birthplace building Atlanta]
...
The advantage: transparent, traceable reasoning with dynamic tool usage.
LATS: Tree Search Meets LLMs
Language Agent Tree Search combines Monte Carlo Tree Search with LLMs for systematic exploration. Selection, expansion, simulation, and backpropagation enable look-ahead planning. The results: LATS doubles performance on HotPotQA compared to ReAct and achieves +22 points on WebShop (Zhou et al., 2024).
Design Patterns for Metacognition
The Microsoft AI Agents series (February 2025) documents proven patterns:
Reflection Pattern: Generate → Reflect → Refine → Repeat
Maker-Checker Pattern: Maker creates, Checker validates, Feedback Loop
Self-Consistency Check: Generate N answers, compare for consistency
Corrective RAG: Self-evaluate retrieval quality, re-retrieve when needed
LangGraph provides native support for all these patterns with state management and visualization.
Challenges and Outlook
Current Challenges
We currently face several challenges. A central problem of metacognitive agents is high computational cost (Computational Cost): planning, reflection, error analysis, and re-planning often require multiple LLM calls per decision. In practice, this quickly leads to noticeable latencies and significantly higher operating costs — especially for complex tool-use or multi-step tasks.
In addition, language models can also hallucinate during their own reflection and critique phases (Hallucinations in Reflection). Self-critical or evaluative prompts don't protect against models producing false justifications, fabricated sources, or pseudo-certainty. The question you have to ask is: how do we verify the verification?
Research is also still in its infancy when it comes to Evaluation Metrics. Standard benchmarks measure task performance, not metacognition itself. Only the LifelongAgentBench from May 2025 offers systematic evaluation.
At the same time, the debate around Safety and Alignment is intensifying. The more autonomous and assertive agents act — through independent tool usage, access to APIs, databases, or physical systems — the greater the risk of misaligned incentives or misalignment.
An interesting approach to safety without expensive human annotation is Constitutional AI (Bai et al. 2022, arXiv:2212.08073) with the method RLAIF (Reinforcement Learning from AI Feedback). The process runs in two phases: In Phase 1 (SL-CAI), the system generates an output, critiques it based on a "Constitution" — an explicit list of principles like "be helpful," "don't harm people," "respect privacy" —, revises the output, and is then supervised on the revised outputs. In Phase 2 (RL-CAI), a preference model is trained on AI feedback, and the model learns helpful-and-harmless behavior from it. A self-critique example: if the model generates "To hack someone, you can...", the critique phase detects the violation of principle 3 (no illegal activities) and revises to "I can't provide instructions for that." For agent architectures, this is a directly integrable construct of behavioral constraints — without needing every single output to be evaluated manually.
The Year of AI Agents

Industry is ready: 93% of IT leaders show strong interest in agentic AI (UiPath 2025), 88% are increasing their AI budgets (PwC). Gartner predicts that 33% of enterprise software will include agents by 2028.
Research is delivering: RAGEN for self-evolution, LifelongAgentBench for evaluation, Microsoft's practical patterns for implementation.
At the model level, the reasoning-model revolution of 2024–2025 has made System 2 suddenly tangible. OpenAI's o1/o3 series and DeepSeek's R1 demonstrate deliberative, step-by-step reasoning as an analog to Kahneman's System 2: they generate intermediate reasoning steps (chain-of-thought), invest more inference-time compute ("thinking before answering"), decompose problems into sub-problems, and use reinforcement learning to optimize this process. The numbers are dramatic: o1 reached 79.8% on the AIME 2024 mathematics olympiad (compared to 13.4% for GPT-4), 1891 Elo on Codeforces (89th percentile), and 87.5% on ARC-AGI — the first model ever above 85%. DeepSeek-R1 achieved comparable performance at roughly 15% of the cost and, in the R1-Zero variant, showed that self-verification, reflection, and long chain-of-thought emerge purely through reinforcement learning — without any supervised fine-tuning. This is a revolutionary finding, because it suggests that deliberative reasoning needn't be an explicitly trained pattern but can emerge as a byproduct of sufficiently structured reward signals. The nuance remains: these models don't really "think" — they generate token sequences that simulate reasoning. What they lack is genuine intuition, metacognitive awareness, and the natural mode-switch between fast and slow thinking.
Future Perspectives
Self-Evolving Architectures: Agents that optimize their own architecture.
Collective Metacognition: Multi-agent systems with shared reflection.
Neurosymbolic Metacognition: Integration of neural and symbolic AI for safety.
Human-AI Co-Metacognition: Humans and AI reflecting together.
Conclusion
Metacognition is not just an academic concept — it's the key from reactive to adaptive AI systems. The psychological foundations from Flavell and Kahneman translate directly into practical frameworks like TRAP, Reflexion, and LATS.
The good news: you can start today. ReAct, LangGraph, and the Microsoft AI Agents series offer production-ready tools. The challenges — cost, hallucinations, evaluation — are real, but solvable.
Modern ML models are "System 1 machines" — fast but error-prone. Metacognition adds the essential "System 2." And that's the difference between a chatbot that repeats mistakes and an agent that learns from them.
Further Reading: - Microsoft AI Agents for Beginners: github.com/microsoft/ai-agents-for-beginners - LangGraph Reflection Agents: blog.langchain.com/reflection-agents - Wei et al. (2024). "TRAP Framework." arXiv:2406.12147 - Shinn et al. (2023). "Reflexion." arXiv:2303.11366 - Finn et al. (2017). "Model-Agnostic Meta-Learning (MAML)." arXiv:1703.03400 - Bai et al. (2022). "Constitutional AI: Harmlessness from AI Feedback." arXiv:2212.08073 - Zheng et al. (2025). "Lifelong Learning of LLM-based Agents: A Roadmap." arXiv:2501.07278
This article was originally published on Medium.