There's a line in the April 2025 Mem0 paper that stuck with me. On the LoCoMo benchmark, the simplest baseline — just dumping the entire conversation transcript into the prompt — hits 72.90% accuracy. Every memory system built in the last two years sat below that line. Mem0 at 66.88%, OpenAI Memory at 52.90%. The only catch was that full-context prompts took 17 seconds and cost 26,000 tokens.
Then, early 2026, Letta showed up with a filesystem approach — grep, search_files, open — and landed at 74.0%. For the first time, a memory system wasn't just faster, it was also more accurate than brute-force stuffing. Three months later, in early April 2026, a ByteDance paper arrived that frames the question differently altogether: what if the model adjusts its own weights during the answer?
In the first part of this series I walked through the memory landscape, and in the second part the cognitive psychology behind it and the current state of consolidation and self-search. This part shows how we measure memory — and why the next idea isn't "yet another memory store," but the model itself.
Part I — The Benchmark Situation
Four Yardsticks
Memory architectures have become genuinely comparable since 2024. Four benchmarks carry most of the empirical discussion:
| Benchmark | Focus | Publication | Scale |
|---|---|---|---|
| LoCoMo | Long-term conversational memory | Maharana et al., arXiv:2402.17753, Feb 2024 | ~300 turns, ~9K tokens, up to 35 sessions |
| DMR (Deep Memory Retrieval) | Single-turn fact retrieval | MemGPT team, 2023 | 60 messages per conversation |
| LongMemEval | 5 memory abilities: info extraction, multi-session reasoning, temporal reasoning, knowledge updates, abstention | Wu et al., arXiv:2410.10813, ICLR 2025 | Long interactive chat sessions |
| RULER | Context length stress test | NVIDIA, RULER Repository | 13 task configurations, 4K to 128K tokens |
Letta captures the shift crisply in their benchmarking blog:
"Memory is more about how agents manage context than the exact retrieval mechanism used."
Letta (2025)
So the interesting question isn't "which database?" but "how does the agent perform under pressure?" And here the numbers tell three stories that only make sense together.
Story A — Full-Context as the Ceiling, Mem0 as the Cost Tradeoff
The Mem0 paper (arXiv:2504.19413) systematically compares memory systems on LoCoMo. Table 2 reads sober and revealing:
| System | LoCoMo J-Metric | Retrieval tokens / query | p95 latency |
|---|---|---|---|
| OpenAI / ChatGPT Memory | 52.90% ± 0.14 | — | — |
| Mem0 Base (Vector) | 66.88% ± 0.15 | ~1,764 | 1.440 s |
| Mem0 Graph | 68.44% ± 0.17 | ~3.5K | 2.590 s |
| Full-Context Baseline | 72.90% ± 0.19 | ~26,000 | 17.117 s |
| Zep / Graphiti | — | >600,000 (storage) | — |
The logic is plain to see: full-context is the brute-force ceiling — everything that happened lands in the prompt, and the model reads it all. That costs 17 seconds and 26K tokens. Mem0 sacrifices 6 accuracy points (66.88 vs. 72.90) and wins 91% latency reduction and 93% fewer tokens per query in return. Zep attacks the other extreme — maximum fact depth through a temporal knowledge graph — at the cost of 600,000+ tokens in storage footprint.
That's the classic memory deal — latency and cost against accuracy. Most product teams are fine with the bargain, even if they never sat down to negotiate it.
Story B — Simple Beats Complex
In March 2026, Letta published a benchmarking paper pitting their own filesystem approach against the established memory scene. The agents get nothing special — just grep, search_files, open, close, and an answer_question tool. The model: gpt-4o-mini, deliberately not the most expensive. The outcome:
- Letta Filesystem: 74.0% on LoCoMo
- Mem0 Graph: 68.5%
- OpenAI Memory: 52.9%
That's the point where the narrative flips. Letta Filesystem even beats the full-context baseline. For the first time, a memory system is not just cheaper and faster than "throw everything into the prompt," but also more accurate. The Letta authors explain it plausibly: CLI tools like grep are massively represented in training data — the model intuitively knows when and how to use them. Specialized memory operations, by contrast, are rare constructs the model first has to learn.
The moral is uncomfortable for memory-infrastructure startups. It's not the database that decides — it's the agent design.
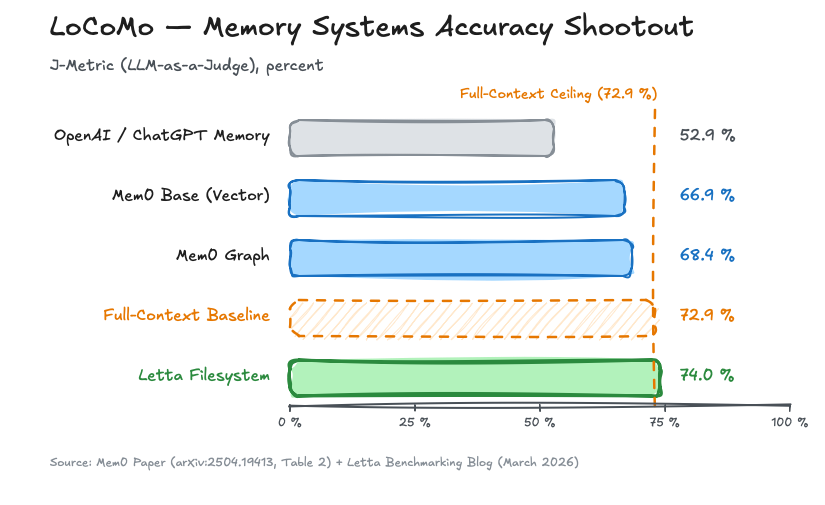 Figure: The LoCoMo shootout. For two years, full-context (72.9%) was the ceiling — until Letta Filesystem broke through it with simple CLI tools.
Figure: The LoCoMo shootout. For two years, full-context (72.9%) was the ceiling — until Letta Filesystem broke through it with simple CLI tools.
Story C — DMR Is Done, LongMemEval Is Now
While LoCoMo became the comparison standard, the old MemGPT yardstick DMR has peaked. Zep/Graphiti scores 94.8% against gpt-4-turbo, and 98.2% against gpt-4o-mini. The Zep authors openly write that DMR has become too easy: single-turn, 60 messages per conversation — fits in any modern context window. They establish LongMemEval as its replacement.
The new bar hurts. GPT-4o reaches about 92% in the offline setup (given only the session containing the answer). In the online setup (the real long-term-memory scenario, many sessions in between), the same baseline drops to ~58%. A 30-to-60-point gap — that's the real memory pain, and it only surfaces with LongMemEval.
Zep lifts models by 18.5 points on LongMemEval, at 90% lower latency. Chain-of-Note plus structured reading adds another 10 points. But the underlying problem remains: long-context models are worse at remembering than their context-window marketing claims.
The RULER Punchline
RULER shows this even more sharply. NVIDIA's 13-task benchmark stresses modern LLMs at 4K, 8K, 16K, 32K, 64K, and 128K tokens. "Effective length" is defined against a performance threshold of 85.6% (Llama-2-7B at 4K). The verdict for models claiming 128K:
- Jamba-1.5-large: >128K effective, 96.0% avg
- Gemini-1.5-Pro: >128K effective, 95.8% avg
- GPT-4-1106-preview: only 64K effective despite a 128K claim, 91.6% avg
This is the finding that keeps the memory community up at night. Modern LLMs score near-perfect on simple needle-in-a-haystack tests — as soon as the tasks get richer, performance collapses well before the advertised limit. Context windows have grown; memory capacity hasn't kept up.
The Wall
Reading the three stories together, there's a wall. The progress we've seen came from better management around the model — smarter stores, cleverer retrieval, leaner prompts. Letta Filesystem is the provisional endpoint of that optimization line: simpler tools, better use. The next percentage points on LongMemEval and RULER will be harder to earn. The weights stay frozen while contexts keep getting longer. And that's exactly where the next idea starts.
This wall has been on my mind for months, because it tells me we've been turning the wrong screw on memory all along — we refined the tooling, but never touched the instrument.
Part II — A New Answer: In-Place Test-Time Training
What ByteDance Is Proposing
On April 7, 2026, Guhao Feng and six co-authors from ByteDance-Seed published "In-Place Test-Time Training" (arXiv:2604.06169). It was accepted as an ICLR 2026 Oral — the top quality tier in the field, reserved for work that delivers substantial new insight. The code is on GitHub under Apache 2.0.
The abstract argues directly against the static deploy paradigm: LLMs in production have no opportunity to adapt to continuous data streams. Test-Time Training (TTT) was proposed as the answer but failed against three barriers — architectural incompatibility, compute inefficiency, and misaligned objectives. In-Place TTT addresses all three.
Fast Weights in the MLPs
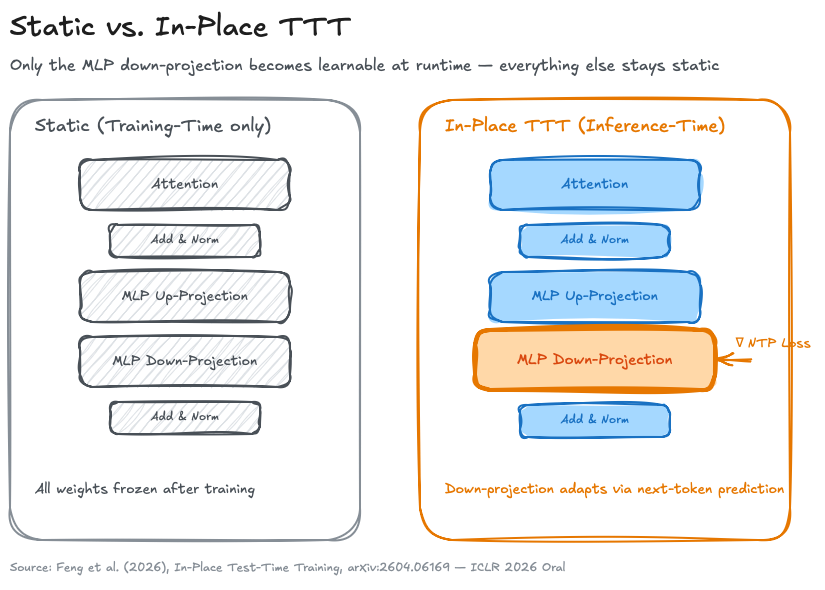 Figure: The structural difference. Only a single matrix per MLP block becomes learnable at runtime — everything else stays static.
Figure: The structural difference. Only a single matrix per MLP block becomes learnable at runtime — everything else stays static.
The architectural trick is remarkably restrained: no new modules, no sidecars, no parallel paths. Instead, the final projection matrix of each MLP block is treated as an adaptable fast weight:
"the final projection matrix of the ubiquitous MLP blocks as its adaptable fast weights"
Feng et al. (2026)
That matrix is allowed to change during inference — all other weights stay static. The effect: the model is frozen at its core but learnable at a clearly defined spot. "Drop-in," as the authors write, compatible with any existing transformer.
The second theoretical advance is the training objective. Earlier TTT approaches used generic reconstruction objectives — what gets reconstructed and what the model is later supposed to do drifted apart. In-Place TTT explicitly couples the update to next-token prediction:
"a tailored, theoretically-grounded objective explicitly aligned with the Next-Token-Prediction task"
Feng et al. (2026)
Sounds like a detail, but it's the reason this approach works on language tasks while earlier TTT variants plateaued.
The third building block: chunk-wise updates, compatible with context parallelism. Instead of touching the weights after every token, the system collects stable updates over chunks — scalable and numerically robust.
What RULER Shows
The evaluation runs exactly where Part I located the wall: RULER. The 4B-parameter model is tested at contexts up to 128K tokens across all 13 task configurations — and via OpenCompass extensions up to 256K. The paper reports "consistently outperforms competitive TTT-related approaches" when pretraining from scratch. The recommended configuration enables TTT on every sixth layer (indices 0, 6, 12, 18, 24, 30, 36), with learning rate 3, chunk size 4096, sequence length 65536.
That closes the loop with Part I. The RULER gap that makes GPT-4 fail at its 64K effective length — that's the target.
More Production-Ready Than You'd Expect
The code stack reads like a current ML infrastructure handbook: PyTorch 2.8, FlashAttention 2.8.3, VeOmni, FSDP2. Recommended target models are Qwen3-8B and LLaMA-3.1-8B — open-weight classics. This isn't a toy; it's a research artifact with a production path. You can reproduce this today.
What This Has to Do With Memory
In the first part I introduced the CoALA framework — five memory types for AI agents, including "parametric" and "episodic" as separate categories. Parametric meant frozen: the knowledge baked into the weights during training. Episodic was whatever happened in the current session.
In-Place TTT blurs that distinction. Episodes from the running context seep into the weights — controlled, locally confined to one projection matrix per layer, but real. The clean taxonomy Tulving and CoALA set down gets a crack.
I find this not just technically interesting but categorically unsettling. The separation between "what the model knows" and "what the agent just remembered" was the reason memory existed as a research field in the first place. Once that line becomes permeable, memory turns into a subset of model training.
Part III — What This Means
The New Fault Line
 Figure: Three layers, three paradigms. Parts 1 and 2 of this series covered the tool and memory layers — with TTT, the series enters the model layer.
Figure: Three layers, three paradigms. Parts 1 and 2 of this series covered the tool and memory layers — with TTT, the series enters the model layer.
Memory now maps cleanly onto three layers — and TTT fills the gap that stood open until a year ago:
| Layer | Paradigm | Examples | Status |
|---|---|---|---|
| Model Layer | Fast weights, runtime-adaptive | In-Place TTT, SleepGate (KV cache) | Research, ICLR 2026 |
| Memory Layer | External stores with consolidation | Mem0, Zep, Letta Sleep-Time, Claude Code Auto-Dream | Production |
| Tool Layer | Agent retrieves its own knowledge | Hermes Session Search, Letta Filesystem | Production |
Part 2 described the memory layer (dreaming, consolidation) and the tool layer (self-search) in detail. Part 3 is the first article in this series that enters the model layer.
Four Open Questions
Right to be forgotten with fast weights. When memory seeps into the weights, how do you guarantee deletion? Machine unlearning is an active research field, but current techniques are expensive and offer no hard guarantees. With external stores, deletion is a DELETE statement — with a modified projection matrix it becomes a retraining or a revert to the last clean checkpoint.
Auditing. Letta Context Repositories (see Part 2) version MEMORY.md like source code — git history, branches, merge conflicts. There is no equivalent tool for fast-weight deltas. How do you diff a projection matrix? Which change was triggered by which user interaction? These are questions whose observability standards are only now starting to emerge.
Coexistence or convergence. Will model-layer memory replace memory-layer stores — or will they complement each other? Economics argues for coexistence in the near term. TTT is likely to stay more expensive than embedding lookups, because it requires gradient updates at inference time. For the hot path of a conversation, that may pay off; for cold storage over weeks, probably not. In the long run, the answer is open.
Trust at the micro level. If the model changes its own weights slightly with every interaction, then every answer is the product of a marginally different version. For the user, that's invisible. For anyone operating the system, the question is no longer "which model delivered this?" but "which trajectory of the model delivered this?". I don't know how to define reproducibility for that.
Closing
The arc of the series is now complete. Part 1 showed the memory architecture landscape. Part 2 showed the cognitive-psychological depth and the current state of consolidation and retrieval. Part 3 shows where the next movement comes from — not from yet another memory store, but from the model itself.
It took me a long time to take this paper seriously. Touching the weights at runtime feels like breaking a taboo at first glance — and that's exactly why it works.
Three questions to take with you:
- Which of the four benchmarks is actually relevant to your product? LoCoMo is the common denominator, but LongMemEval measures what your users actually experience.
- If LongMemEval is the honest bar, why are most memory stacks still built around DMR-friendly single-fact retrieval patterns?
- What would it mean for your governance processes if the model learns and forgets during user interactions?
These answers won't stay research questions much longer. An ICLR Oral paper with Apache 2.0 code on Qwen and LLaMA is no longer a preview in this industry — it's a starting gun.
Further Reading
- Feng, G. et al. (2026). "In-Place Test-Time Training." arXiv:2604.06169 — ICLR 2026 Oral. Code: github.com/ByteDance-Seed/In-Place-TTT
- Maharana, A. et al. (2024). "Evaluating Very Long-Term Conversational Memory of LLM Agents" (LoCoMo). arXiv:2402.17753
- Wu, D. et al. (2024). "LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory." arXiv:2410.10813 — ICLR 2025
- Rasmussen, P. et al. (2025). "Zep: A Temporal Knowledge Graph Architecture for Agent Memory." arXiv:2501.13956
- Chhikara, P. et al. (2025). "Building Production-Ready AI Agents with Scalable Long-Term Memory" (Mem0). arXiv:2504.19413
- Lin, K. et al. (2025). "Sleep-time Compute: Beyond Inference Scaling at Test-time." arXiv:2504.13171 — Letta + UC Berkeley
- NVIDIA. "RULER: What's the Real Context Size of Your Long-Context Language Models?" github.com/NVIDIA/RULER
- Letta Blog (2025). "Benchmarking AI Agent Memory." letta.com/blog/benchmarking-ai-agent-memory
- Letta Blog (2025). "Letta Leaderboard." letta.com/blog/letta-leaderboard
This article was originally published on Medium.