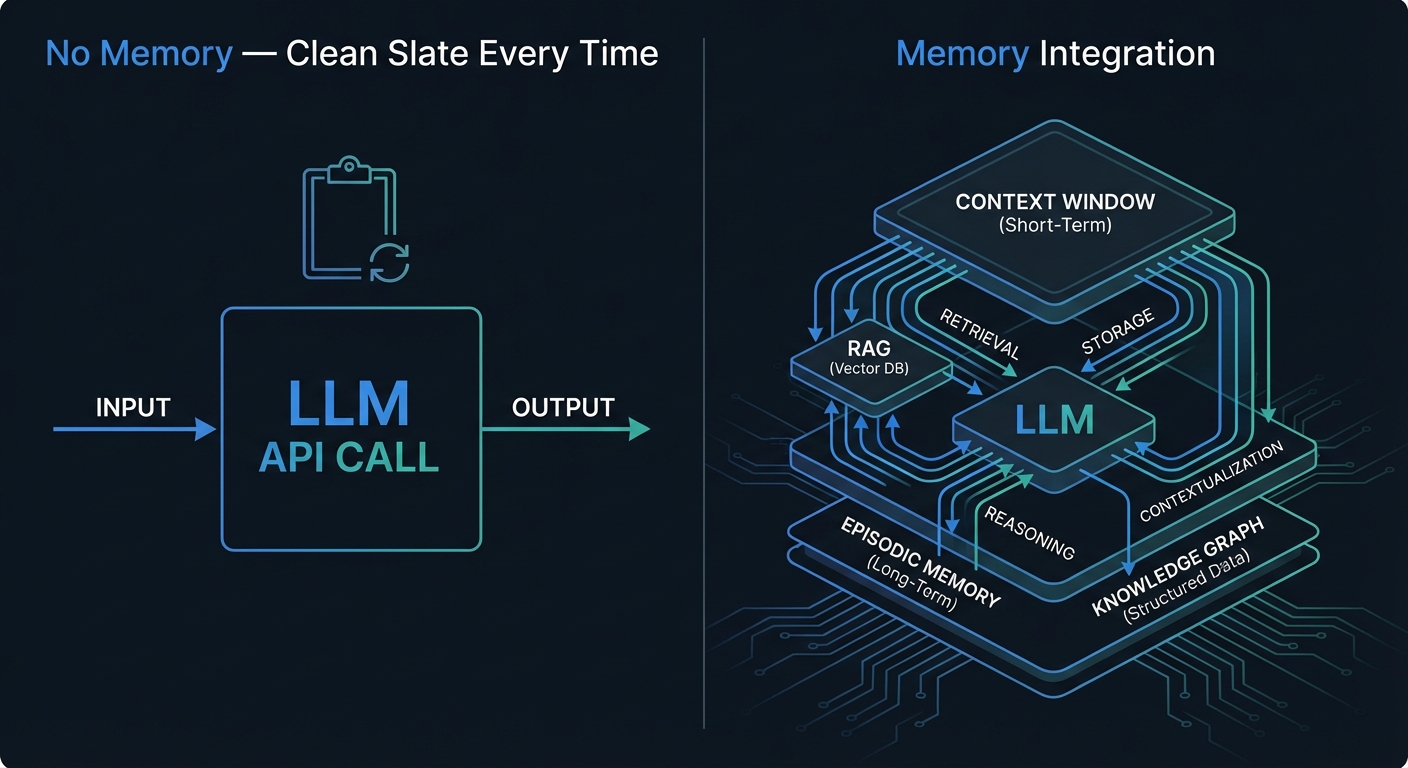
Imagine calling your best developer colleague every morning — and he remembers nothing from yesterday. No context, no project knowledge, no memory of yesterday's decisions. You explain everything from scratch. Every single time.
That's the reality with LLM-based AI agents. Every API call is a clean slate. No state carries over to the next request. And yet we're building systems meant to replace knowledge workers — systems expected to stay productive over hours, days, weeks.
The stateless problem is the fundamental obstacle on the road to real AI agents. And there's now an entire landscape of solutions — from radically simple to highly complex. Here I'll show you which memory architectures exist, how they differ, and when you need which.
The Core Problem: LLMs Forget Everything — Always, Immediately
A transformer-based LLM performs a single forward pass for each API call:
Input Tokens → [Transformer Forward Pass] → Output Tokens
↓
No internal state remains
After that pass, everything is gone. The model weights are static — frozen during training, immutable at runtime. And the context window — everything you send the model in a request — exists only for that one request.
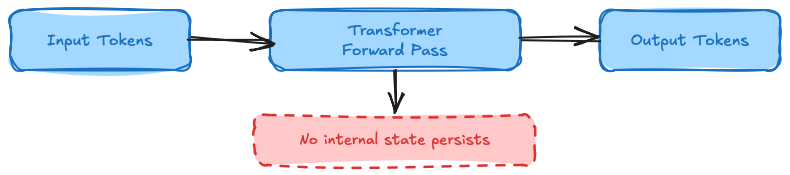 Every LLM API call is an isolated forward pass. No state persists between requests.
Every LLM API call is an isolated forward pass. No state persists between requests.
The model has exactly two knowledge sources:
| Source | Properties |
|---|---|
| Training weights | Static, frozen, can be outdated |
| Context window | Ephemeral, per-request only, capacity-limited |
Between these two sits a gap: there's no medium-term, persistent, dynamically updatable memory. That's precisely what memory architectures address.
Five Memory Types — What an Agent Needs
The CoALA Framework (Cognitive Architectures for Language Agents, Sumers et al. 2023) defines five memory types for AI agents — inspired by cognitive psychology, particularly Endel Tulving's work on memory systems:
| Type | What | Example |
|---|---|---|
| Parametric | Training weights | "Paris is France's capital" |
| In-Context | Context window | System prompt + current conversation |
| Episodic | Past interactions | "User asked about Python debugging yesterday" |
| Semantic | External factual knowledge | RAG documents, company wiki |
| Procedural | Learned behavior | RLHF policies, tool usage patterns |
Most chatbots use only parametric plus in-context memory. That's enough for simple Q&A. But an agent working on a project over days needs all five: it must remember past interactions, retrieve factual knowledge, and know how to approach specific tasks.
That's the real leap from "chatbot" to "agent."
Context Window: Working Memory and Its Limits
The context window is an LLM's primary working memory. And it's growing fast:
| Model | Context Window |
|---|---|
| GPT-3.5 (2023) | 4K Tokens |
| GPT-4 (2023) | 128K Tokens |
| Claude 3/4 (2024/25) | 200K Tokens |
| Gemini 2.0 (2025) | 1M+ Tokens |
Sounds great. But more tokens don't automatically mean better understanding. Liu et al. demonstrated in 2023 a critical problem — the so-called "Lost in the Middle" phenomenon: LLMs process information at the beginning and end of the context significantly better than information in the middle. Filling a giant context window doesn't solve the problem — it just relocates it.
That's why there are three practical strategies for efficient context usage:
Conversation Summarization compresses older messages to save space. Trade-off: detail vs. capacity.
Sliding Window keeps only the last N messages. Simple to implement, but systematically forgets everything outside the window.
Context Compression — algorithms like LLMLingua (Jiang et al. 2023) remove less informative tokens from the context. Compressed context with the same information content.
All of these remain ephemeral. After the request, everything's gone. For persistent knowledge, you need more.
RAG: Semantic Memory Externalized
Retrieval-Augmented Generation (RAG), introduced by Lewis et al. (2020), is the most widely known approach for persistent factual knowledge. The principle:
Query → [Embedding] → [Vector DB Search] → Top-K Documents
→ [LLM Prompt + Documents] → Answer with source citation
 The RAG pipeline externalizes semantic knowledge into a searchable vector database.
The RAG pipeline externalizes semantic knowledge into a searchable vector database.
RAG's strengths: Up-to-date knowledge, citable sources, no retraining costs when knowledge changes. Vector databases like Pinecone, Weaviate, Chroma, and pgvector are production-ready and scale well.
RAG's weaknesses: Retrieval quality is critical — poor embeddings return irrelevant documents. The "Lost in the Middle" problem applies here too. And most importantly: RAG has no state. It has no memory of past interactions.
RAG = "looking up" — not real "remembering"
That's an important conceptual distinction. RAG gives an agent access to factual knowledge, but not to its own history, its own decisions, its own evolving context.
MemGPT and Letta: Self-Managed Memory
The conceptual breakthrough came in 2023 with MemGPT (Packer et al., ICLR 2024). The core idea: virtual memory paging from operating systems — applied to LLMs.
Instead of an application deciding from outside what enters the context, the agent itself manages its memory across three tiers:
┌─────────────────────────────┐
│ Core Memory │ Always in context
│ (Persona + User Profile) │ LLM edits directly
├─────────────────────────────┤
│ Recall Memory │ Searchable
│ (Conversation history) │ Agent retrieves on demand
├─────────────────────────────┤
│ Archival Memory │ Unlimited
│ (Vector-indexed) │ Agent archives autonomously
└─────────────────────────────┘
 MemGPT's three memory tiers. The agent decides via function calling what moves between tiers.
MemGPT's three memory tiers. The agent decides via function calling what moves between tiers.
The revolutionary part: the agent decides via function calling what moves between tiers. It's not a passive recipient of context — it's an active memory manager. Conceptually, this mirrors Baddeley's "Central Executive" in human working memory — the control system that decides what gets attention and what gets stored.
MemGPT has since evolved into Letta. As of December 2025, Letta is the #1 open-source agent platform on Terminal-Bench. In February 2026, Context Repositories were added — Git-based versioning for agent memory. That means: memory with full commit history, branching, and rollback.
Memory-as-a-Service: Mem0 and Zep
If you don't want to build your own memory infrastructure, Mem0 and Zep offer production-ready managed services — with very different approaches.
Mem0 — Hybrid Vector + Knowledge Graph
Mem0 combines vector embeddings with a knowledge graph. On every interaction, the system automatically extracts facts, preferences, and entities, stores them as structured memory objects, and makes them retrievable via semantic search plus graph lookups.
The benchmarks are compelling:
- 26% better than OpenAI Memory on LoCoMo benchmark (66.9% vs. 52.9%)
- 90% token cost reduction (~1.8K vs. 26K tokens)
- 91% lower p95 latency (1.44s vs. 17.12s)
- 41K GitHub Stars, 186M API calls in Q3 2025, $24M in funding
Zep / Graphiti — Temporal Knowledge Graph
Zep takes a different approach. Instead of only storing WHAT is true, Zep also stores WHEN it was true. The underlying Graphiti graph (arXiv:2501.13956) models facts with validity time ranges.
Example: "User lived in Berlin 2020–2023, moved to Munich in 2023." When an address changes, the old information isn't overwritten — it receives an end date, and the new information gets a new edge. Non-lossy updates, full audit history.
- 94.8% on DMR Benchmark (MemGPT: 93.4%)
- Sub-200ms latency — optimized for Voice AI
- Integrated with AWS Neptune in September 2025
| System | Paradigm | Latency | Benchmark | Open Source |
|---|---|---|---|---|
| Mem0 | Vector + Graph | p95: 1.4s | 66.9% LoCoMo | Core: yes |
| Zep/Graphiti | Temporal Knowledge Graph | <200ms | 94.8% DMR | Graphiti: yes |
| MemGPT/Letta | 3-Tier Virtual Memory | — | Terminal-Bench #1 | yes |
| ChatGPT Memory | Fact Extraction | Low | 52.9% LoCoMo | no |
| Claude Code | Markdown Files | Instant | — | — |
Mem0 is optimized for scale and cost. Zep is optimized for temporal consistency and audit requirements.
Agent State Management with LangGraph
Beyond memory, agents need something else: state. That's a conceptually important distinction:
| Memory | State | |
|---|---|---|
| Focus | What has been remembered? | Where are we in the process? |
| Temporal | Past | Current moment |
| Example | "User prefers Python" | "We're on step 3 of 5" |
| Persistence | Long-term | Often short-lived (workflow duration) |
LangGraph, LangChain's framework for agent graphs, solves state management with a typed state object that flows through the entire graph:
class AgentState(TypedDict):
messages: Annotated[list, add_messages] # append
plan: str # replace
tools_called: list[str] # append
 LangGraph's typed state management with reducer functions and checkpointing.
LangGraph's typed state management with reducer functions and checkpointing.
Each state field has a reducer — add_messages appends new messages, plan replaces the previous plan. State updates are deterministic and free of race conditions.
The killer feature is checkpointing: every step is saved (PostgreSQL, Redis, or in-memory for dev). If something goes wrong, you can jump back to any checkpoint. Plus human-in-the-loop at every checkpoint — the agent pauses, you inspect, you decide whether it continues.
Deterministic, auditable state transitions instead of opaque memory black boxes.
Memory in Real Products
Theory is useful. But what does memory look like in products you can actually use today?
ChatGPT Memory
ChatGPT decides autonomously what to remember. Technically, it's a simple memory list in the system prompt — no complex vector search. Since May 2025, there's a "Memory Dossier" where users can inspect what ChatGPT has stored about them. 200M+ weekly active users get memory as self-service.
Claude Code — MEMORY.md
Radically simple: plain Markdown files on disk. A CLAUDE.md file contains instructions, rules, and project preferences. Claude Code reads it automatically on session start — only the first 200 lines. Version-controllable, human-readable, human-editable, no infrastructure required.
This is the approach I use daily. Sometimes the simplest solution is the best.
Google NotebookLM
A completely different approach: memory is tied to user-uploaded documents. Gemini with a 1 million token context window. Strictly source-based — the system doesn't hallucinate beyond its own sources. This makes NotebookLM an interesting edge case: maximum control over "memory" through explicit document selection.
Three Paradigms — And When You Need Which
From the landscape of approaches, three fundamental paradigms emerge:
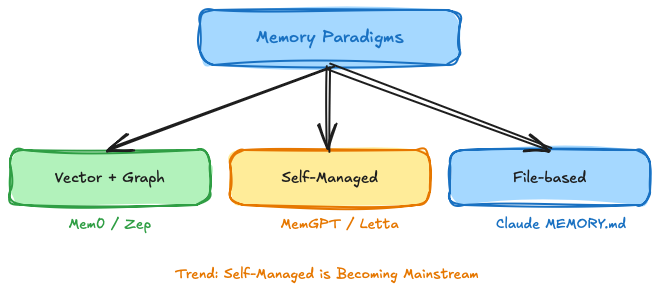 The three competing memory paradigms and their representatives.
The three competing memory paradigms and their representatives.
Paradigm 1: Vector + Graph (Mem0, Zep) — Rich in semantic and temporal relationships, scalable, but infrastructure-intensive. Right when you need persistent, structured memory across many users.
Paradigm 2: Self-Managed Memory (MemGPT/Letta) — The agent controls its own memory. Maximum autonomy and flexibility. Right when you're building agents with genuine long-term autonomy.
Paradigm 3: File-based (Claude Code MEMORY.md) — Radically simple, transparent, editable. Right when transparency and simplicity matter more than scale.
Decision matrix:
| Use Case | Recommendation |
|---|---|
| Building an agent framework | LangGraph + Mem0 or Zep |
| Chatbot with memory | Mem0 (simpler) or Letta (more control) |
| Enterprise with audit requirements | Zep (temporal consistency, non-lossy) |
| Quick and simple | MEMORY.md approach |
| Source-based analysis | NotebookLM |
A-MEM: The Zettelkasten Method for AI
One approach deserves special mention because it's conceptually fascinating: A-MEM (Xu et al. 2025, NeurIPS 2025, arXiv:2502.12110).
The idea: memory organizes itself using the Zettelkasten method — the system of sociologist Niklas Luhmann. Instead of storing memories as a flat list, each memory is a "note" with descriptions, keywords, tags, and cross-references to related memories. The agent creates and links memory entries dynamically — memory as an associative network rather than a linear list.
The result according to the paper: doubled performance on complex reasoning tasks compared to traditional memory systems.
Memory as a network rather than a list — that's a fundamental conceptual shift.
Five Open Challenges
With all the progress, there are still unsolved problems.
Privacy and GDPR. What can a system remember about a user? How is the "right to be forgotten" technically guaranteed? Consent management for memory systems is still in its infancy.
Hallucination in memory. LLMs can "extract" false memories and store them persistently. Self-critique can also be hallucinated. Who verifies the verification? Garbage in memory leads to permanent, hard-to-correct errors.
Scaling. Episodic memory after millions of interactions? Retrieval quality degrades as size grows. Vector databases and knowledge graphs become harder to search at scale.
Conflicts and consistency. What happens with contradictory memories? What when facts change? Zep addresses this with temporal edges — but parallel agent instances generating conflicting memories remain an open problem.
Costs. Multiple memory lookups per request increase latency and cost. Mem0 shows that intelligent memory can actually reduce costs though — 90% token reduction through precise contextualization instead of naive context-window stuffing.
Conclusion: Memory Is Becoming Table Stakes
"Contextual memory will become table stakes for operational agentic AI"
VentureBeat (2026)
That quote nails it. Memory is no longer an optional feature — it's becoming a baseline requirement. 85% of organizations already use AI agents in at least one workflow. The global AI agents market is growing from $7.6B (2025) to an expected $52.6B by 2030. And memory management is one of the top success factors for productive AI agents.
What I find particularly exciting about this development: memory is becoming measurable. LoCoMo, DMR, LongMemEval, Context-Bench — standardized benchmarks now exist. That's the difference between "sort of works" and engineering.
The trend points clearly toward self-managed memory — systems where the model itself decides what to remember. MemGPT started that in 2023, A-MEM is developing it further. Claude Code (Anthropic, 2026) implements a similar pattern with Auto-Dream — a background consolidation cycle that automatically reorganizes memory between sessions. But that raises a question we'll be wrestling with for a long time:
Who controls the memory — the user, the developer, or the model itself?
The answer to that question will determine how trustworthy and controllable AI agents in production become. Not a trivial tradeoff.
Further Reading
- Packer, C. et al. (2023). "MemGPT: Towards LLMs as Operating Systems." arXiv:2310.08560 — ICLR 2024
- Sumers, T.R. et al. (2023). "Cognitive Architectures for Language Agents." arXiv:2309.02427 — TMLR 2024
- Xu, W. et al. (2025). "A-MEM: Agentic Memory for LLM Agents." arXiv:2502.12110 — NeurIPS 2025
- Mem0 Team (2025). "Building Production-Ready AI Agents with Scalable Long-Term Memory." arXiv:2504.19413
- Zep Team (2025). "A Temporal Knowledge Graph Architecture for Agent Memory." arXiv:2501.13956
- Liu, N.F. et al. (2023). "Lost in the Middle: How Language Models Use Long Contexts." arXiv:2307.03172
- Nous Research. "Hermes Agent: Memory." hermes-agent.nousresearch.com
This article was originally published on Medium.