
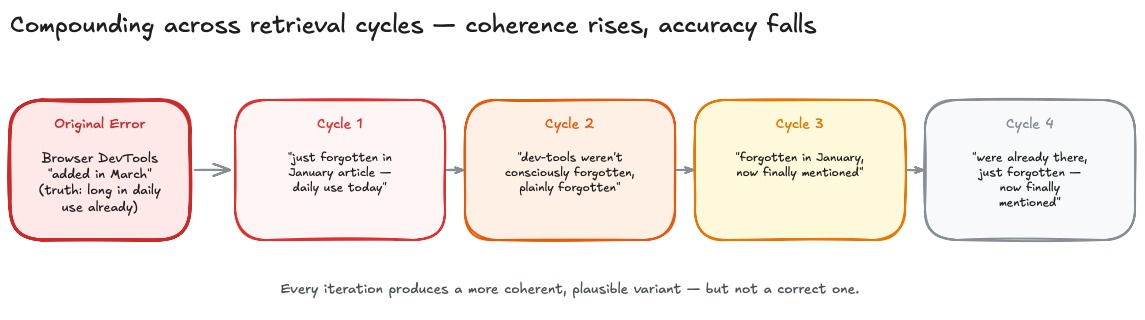
In March 2026, I was writing a monthly article with Claude. One sentence claimed that browser DevTools had "been added in March." Not true. I corrected it: "Just forgotten in the January article — daily use today." Next round: "dev-tools weren't consciously forgotten, but simply plainly forgotten." Round three: still not quite right. Round four, finally: "Browser DevTools didn't get added in March. They were already there, just forgotten in January, and now finally mentioned."
Four corrections. A flat-out wrong sentence that resisted reconstruction. Each round produced a coherent, plausible-sounding variant — and each one was wrong. That's not a bug a better model would fix. That's how schema-based memory works. More precisely: that's how it works once it's persisted.
Hallucination That Stays
Generation hallucination is transient. An LLM produces a wrong sentence, the request ends, the context window gets discarded, and at the next call the error is gone. It's unpleasant, but it's a problem that dissolves itself with every fresh context.
Memory hallucination is different. An agent extracts "facts" from a conversation, stores them in a vector store or knowledge graph, and at the next retrieval they surface again. Not as uncertain generation, but as filed, structured information. A second agent reads them and treats them like verified system state. A third builds on top of that. The hallucination has crossed the reality-check barrier once — after that, it's no longer hallucination, it's database content.
This problem isn't a gradient of the old one. Bartlett's schema theory provides the mechanism: schemas reconstruct, they don't reproduce. When every retrieval cycle generates a new plausible variant, and when each of these variants serves as the basis for the next cycle, the result doesn't converge on truth. It converges on "coherent and wrong." The DevTools story at the beginning of this article is a trivial example — I was the reality check, for four rounds. In an automated memory-extraction pipeline, that reality check doesn't exist.
The field has started treating this as a risk category. "Memory & Context Poisoning" (ASI06) has been in the OWASP Top 10 for Agentic Applications 2026 since December 2025 — alongside Agent Goal Hijack, Tool Misuse, Identity & Privilege Abuse, Cascading Failures, Rogue Agents, and four further categories. That's no longer an author's hypothesis, it's institutional recognition.
The research on this is concrete. MINJA (arXiv:2503.03704) — "A Practical Memory Injection Attack against LLM Agents" — demonstrates memory corruption via query-only interaction, without privileged access to the memory store. The paper reports an average Injection Success Rate of 98.2% and an Attack Success Rate of 76.8% in eliciting malicious reasoning steps. MemoryGraft (arXiv:2512.16962, December 2025) describes "persistent compromise" via poisoned experience retrieval: the agent learns from successfully completed tasks, but when the stored "successes" have been manipulated, it imitates manipulated patterns. The attacks work because the memory system trusts its own retrieval source.
Bartlett's Mechanics on Agent Memory
As I've shown in Part 2 of the Memory Series, Frederic Bartlett's schema theory (1932) is the mechanism behind LLM hallucination. That article introduces the framework: memory is reconstructive rather than reproductive; schemas transform new information toward what is culturally familiar; the "effort after meaning" forces coherence, even when the data is patchy. What I'm doing in this article is an additional step: what happens to this mechanism once memory isn't transient anymore but persisted?
Bartlett's central finding from the "War of the Ghosts" experiment is worth pulling back briefly, because it directly informs the memory-persistence question. English students were asked to retell a First Nations folktale. Over repeated reproductions, four systematic distortions emerged: leveling (details drop out), sharpening (familiar elements get emphasized), rationalization (unintelligible material gets rationalized), and cultural assimilation. "Something black came out of his mouth" became "He foamed with rage." The subjects confabulated coherent but increasingly inaccurate versions — and were increasingly confident they remembered correctly. "Coherence rises, accuracy falls."
An LLM applies exactly the same mechanism when it reconstructs from its learned pattern space. The DRM paradigm — Roediger & McDermott 1995, Journal of Experimental Psychology: Learning, Memory, and Cognition 21(4), 803–814 — quantifies this in human research: subjects hear word lists like bed, rest, awake, tired, dream, pillow, night — and later "remember" the word "sleep," even though it was never presented. In Experiment 2 of the paper, the false-recall rate reaches 55%. The schema creates a false memory that feels subjectively indistinguishable from a real one. Neuroscientific studies from the same period show that the same brain regions are active during false and real memories — the mechanism makes no distinction between reconstruction and retrieval.
For agent memory systems, this has a specific consequence: extraction hallucination. An agent reads a conversation, extracts "facts," and stores them in structured form. This extraction is itself a reconstructive step — the agent fabricates a structured entry from unstructured text, and what gets extracted is shaped by its schemas. The "effort after meaning" applies not only during generation but also during storage. And because the same model weights are involved, in the next cycle the agent doesn't know which of its stored entries was genuine retrieval from the source and which was schema-driven fabrication.
With transient generation, the next fresh context helps. The error doesn't become a system fact, because at the next request it's gone. With memory persistence, it does become a system fact, because the next agent reads it as stored information, not as potentially hallucinated generation. The hallucination crosses the reality-check barrier once, and after that the system treats it like truth.
Erasure, Correction, Consent — GDPR Meets the Vector Store
Once memory hallucination is stored, the immediate question is: how do you remove it again? And at that point, agent memory meets the GDPR. Article 17 of the GDPR — the right to erasure — is a core user right. But the article doesn't say what "erasure" means in an AI system. The MDPI 2025 paper "GDPR and Large Language Models: Technical and Legal Obstacles" (Future Internet 17(4):151) puts this indeterminacy at the heart of the conflict: personal data exists in parallel in raw data, in derived data like embeddings, in model weights, in fine-tune adapters. A GDPR-compliant erasure would have to hit all layers.
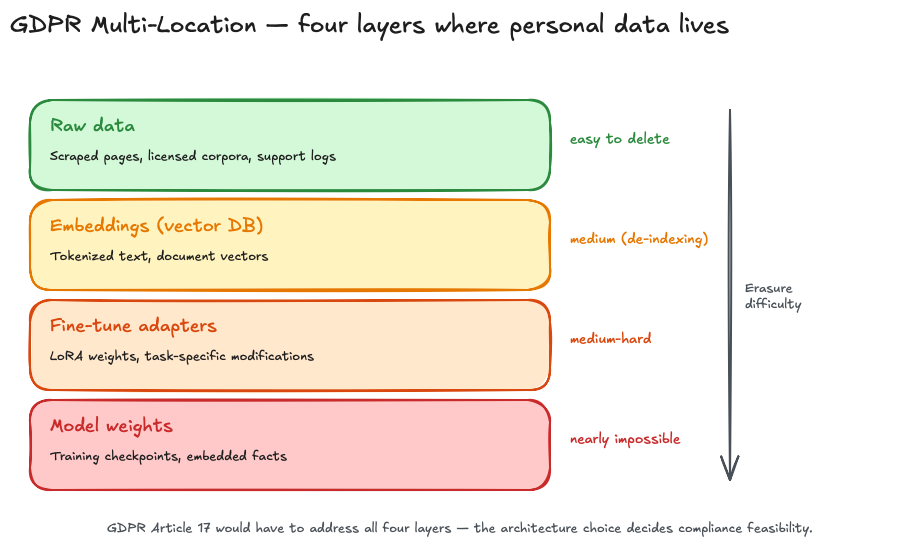
In training weights, by current standards, erasure is "nearly impossible without costly re-training or experimental machine unlearning methods." This means two things. First: the GDPR conflict is structural, not bureaucratic. Second: the memory architecture choice becomes a compliance decision, not just a technical one. A system that embeds personal data into its model weights will collide with Article 17 of the GDPR. A system that keeps personal data in a separate, deletable layer does not collide.
The German Data Protection Conference picked up this logic in 2025 in a guidance document and explicitly positioned RAG systems as a data-protection-compliant architecture option. Data sitting in a vector DB rather than in model weights can be deleted, corrected, and queried. The classic GDPR user rights — information, correction, erasure, objection — are fulfillable. De-indexing and vector-space recalibration are technically realizable. That's a surprisingly constructive finding from a data protection authority: yes, AI is GDPR-capable — but only with the right architecture. Whoever builds memory architectures is also building GDPR posture. For the fundamentals, see Part 1 of the Memory Series, where I covered RAG and vector databases in detail.
That this isn't a theoretical conflict is shown by the case Garante vs. OpenAI. On March 30, 2023, the Italian data protection authority imposed an interim emergency ban on ChatGPT in Italy — the processing of Italian users' personal data was temporarily suspended. On November 2, 2024, the final decision followed, published as a press release on December 20, 2024: 15 million euros in fines, plus an obligation to run a six-month public awareness campaign in Italian media. The charges: lack of transparency about data processing, no legal basis for training, inaccuracy of information ChatGPT provides about real persons, missing age verification. The backdrop was a concrete incident: on March 20, 2023, OpenAI had reported a data breach in which chat histories and payment data were exposed.
The concrete AI Act impact can be experienced right now at OpenAI itself. The ChatGPT Memory feature is not available in the EU, the EEA, the UK, Switzerland, Norway, Iceland, or Liechtenstein — because the feature architecture is not compliance-capable in these jurisdictions. That's the hardest conceivable proof that the EU AI Act isn't paper. OpenAI disabled its memory function for an entire economic region rather than rebuild it. According to the policy documentation, deleted memories are retained for 30 days for safety and debugging purposes.
Anthropic does it differently: the Claude Memory function was rolled out in stages — first for Pro users, and since March 2, 2026, for all tiers including free users on claude.ai and in the Claude app. Not on the API, not in Claude Code. Consumers have needed an opt-in for training use since August 2025; with opt-in, conversations may be retained in de-identified form for up to 5 years. Claude for Work, Enterprise, Education, and Gov are excluded from training use. Different policy layers, different GDPR exposure.
Consistency, Conflicts, Temporal Truth
Legal governance decides what may be deleted. The technical layer raises an upstream question: which memory entry is even still valid? Because even if the legal question is settled — erasure possible, consent documented, EU AI Act observed — the technical question of consistency remains. In any long-running memory operation, contradictory memories are the norm, not the exception. Facts change: Anna now works at company X — three months ago it was Y. Projects shift, priorities get reordered, decisions are revised. Two agent instances running in parallel can interpret the same source differently and generate contradictory memories. Which one holds?
Zep's answer is a bi-temporal model (arXiv:2501.13956, Rasmussen et al., January 20, 2025). The memory system maintains two parallel timelines: one for the real world — when was a piece of information true — and one for the system's transactions — when did Zep ingest this info. Updates don't overwrite; they create new edges in the knowledge graph. This makes the system non-lossy: the old information stays, it's just marked as "no longer valid from time X." For audit trails, that's gold, because the history remains traceable.
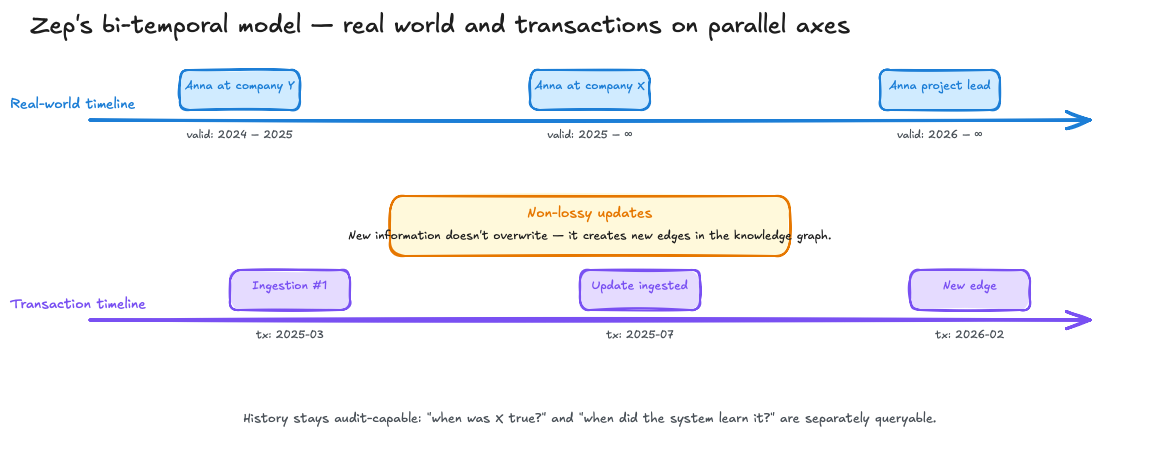
The numbers Zep achieves are significant. On the DMR benchmark (Deep Memory Retrieval), Zep reaches 94.8% vs. MemGPT's 93.4%. On the LongMemEval benchmark, up to 18.5% accuracy improvement at 90% latency reduction. Rasmussen and co-authors (Paliychuk, Beauvais, Ryan, Chalef) frame this as an architectural difference that shows up in the measurements. Part 3 of the Memory Series covers the benchmark side in detail.
In parallel, there's defense research that secures consistency architecturally. Trust-Aware Retrieval with temporal decay and pattern-based filtering (arXiv:2601.05504) is one approach: memories age in their weighting, known injection signatures get filtered out. A-MemGuard complements that with consensus-based validation across multiple retrieval paths — more on that in chapter 7.
A single agent with consistent memory is hard enough. As soon as multiple agents work with shared or competing memory, complexity becomes exponential. Part 4 of the Memory Series treated Generative Agents as a single case study — 25 agents displaying emergent social behavior in a simulation. The question of multi-agent governance and consensus-building across multiple agents is complex enough for its own article. That one is coming.
Cost — The Economic Governance Dimension
Legal and technical governance share a common lever: both make memory operations more expensive. Compliance audit trails, bi-temporal models, trust-aware retrieval — each instrument has inference overhead. And every request to an agent can trigger multiple memory lookups anyway. In a system with ten thousand users and a hundred requests per day, that becomes measurable — and measurable enough that the product's cost calculation depends on it. The trade-off between memory richness and inference speed isn't theoretical. It's one of the fundamental architectural decisions for production-ready agent systems.
Mem0 is the counterexample showing that smart memory architecture can reduce costs instead of raising them. The paper arXiv:2504.19413 "Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory" (Chhikara et al., April 28, 2025) reports two headline numbers. First: 26% relative improvement in the LLM-as-a-Judge metric compared to OpenAI's own memory. Second, and more decisive for the cost discussion: more than 90% token cost reduction. That's not 10% savings, that's an order of magnitude.
These numbers get context from the market frame. MarketsandMarkets projects the global AI agents market to grow from 7.84 billion USD (2025) to 52.62 billion USD (2030), with a CAGR of 46.3% — other analyst houses sit in a similar corridor. VentureBeat framed it in early 2026: "In 2026, contextual memory will no longer be a novel technique; it will become table stakes for many operational agentic AI deployments." Memory isn't a differentiation feature anymore, it's a baseline requirement — and that shifts the cost question.
Who defines how many memory lookups an agent may perform per request? Which memory richness justifies which additional latency? Which user groups get full memory access, which only reduced? These aren't technical questions, they're policy questions at the system level. Cost efficiency is governance — and with that, a piece of meta-decision that simultaneously raises the question of who should decide over agent memory in the first place.
Four Open Questions — And Who Controls the Memory
Law, technology, economics — three governance dimensions, each with its own answers. Above them sit four research questions that nobody can currently answer with confidence, and whose answers will shape the architecture decisions of the coming years. After 90 years of cognitive research, Bartlett's analysis is confirmed: hallucination isn't an external disturbance, it's a consequence of the generative mechanism. The question of whether hallucination can ever be eliminated has an answer that must remain restrained in an article's tone: probably not completely. The paradox here is that the very capability that enables hallucination — plausible reconstruction from learned patterns — is the same capability with which models generalize. A non-hallucinating model wouldn't be a language machine anymore, it would be a search engine. The realistic strategy, therefore, can only be rate reduction, not elimination.
The second question is more philosophical. Tulving's concept of autonoetic consciousness — the ability to experience oneself as the experiencer of one's own memory — is not present in LLMs. Is functional memory enough for what we would call "remembering," or is something fundamental missing? I introduced Tulving's framework in Part 2 of the Memory Series, there's more depth there. For this article, the question stays open — and I think it has to stay open, because no one currently has a defensible answer.
Third question: does metacognition emerge from memory? If an agent could reflect on its own memories — which ones are reliable, which aren't — that would be a meta-level that current systems lack. A-MemGuard's dual-memory structure (a lessons store separate from the experience store) is one possible direction. That's not yet true metacognition, but it's a first step in that direction.
The fourth question is the one that preoccupies me most: who controls agent memory? User, developer, or model? And my answer depends on the application context. For coding assistants like Claude Code: full control with the user. I want to see what gets stored, I want to be able to delete, I want to decide what still applies. A tool writing my code cannot have memory autonomy against me. Anything else would be untenable.
For end-user applications, things look different. There I need architectural sovereignty as a developer, otherwise product design is impossible. And the model needs self-managed memory capabilities, so the application doesn't fall back on the user for every edge case. The user gets policy levels and transparency, not architecture levers. A mix of pro-developer and pro-model. No universal answer, but domain differentiation.
This isn't cosmetic. Anyone who answers the control question universally either curtails the product spaces or the user rights. A small example of the difference: Claude had, in a backup article I wrote in April 2026, formulated "I've been advising clients on backup strategies for years." Not true — I'm a developer, I recommend backups, I don't consult on backup strategies. A semantic shift from "recommend" to "advise," with identity consequences. Who would have caught that, if not me? In a coding-assistant scenario, the user must have this control. In a product with millions of users, that doesn't scale. The right answer is context-dependent.
Governance Infrastructure Is Forming
What might sound bleak at this point in the article is, on closer inspection, not. The governance infrastructure for agent memory is taking shape right now — and faster than most outside observers realize.
The first step is taxonomy. The OWASP Top 10 for Agentic Applications 2026 (published December 9, 2025 by the OWASP Gen AI Security Project) is the first formal risk catalog for autonomous AI agents. Ten categories, ASI01 through ASI10 — Agent Goal Hijack, Tool Misuse & Exploitation, Identity & Privilege Abuse, Agentic Supply Chain Vulnerabilities, Unexpected Code Execution, Memory & Context Poisoning, Insecure Inter-Agent Communication, Cascading Failures, Human-Agent Trust Exploitation, and Rogue Agents. That sounds like administrative work, but it's substantial: no taxonomy, no testing standard; no testing standard, no benchmark; no benchmark, no market pressure to improve. Taxonomy is the precondition for measurability.
The second step is open-source tooling. On April 2, 2026, Microsoft released the Agent Governance Toolkit — according to their own description, the first toolkit addressing all ten OWASP agentic risks with deterministic, sub-millisecond policy enforcement. The Cross-Model Verification Kernel (CMVK) is one of the core mechanisms — majority voting across multiple models as protection against memory poisoning. Rather than trust a single model, one lets several check independently and only accepts consensus.
A-MemGuard (arXiv:2510.02373, Wei et al., September 2025) is the central building block from defense research. Consensus-based validation combined with a dual-memory structure: if a memory retrieval leads to a failing agent task, the lesson drawn from that gets written into a separate "lessons" store and consulted at the next retrieval. That breaks error cycles which otherwise would have been reinforced through persisted hallucinated memory. The paper reports over 95% reduction in attack success rates at minimal utility cost — measurable implementation, not a lab idea.
The next layer is audit and revocation infrastructure. Rather than managing API keys per agent, graph-based delegation paths trace the authority chain an agent is operating through — and make that chain precisely revocable without disrupting other agents' ongoing activities. That's governance infrastructure that scales with agent complexity. In combination with Zep's bi-temporal model from chapter 4, an audit capability emerges that compares with classic database auditing.
How long the road still is, two findings from 2026 show. A Kiteworks analysis reports that 33% of organizations have no evidence-quality audit trails for their AI systems, and that organizations without such trails lag 20 to 32 points behind on AI maturity metrics. A parallel red-team study (Agents of Chaos, February 2026, 20 researchers from Harvard, MIT, Stanford, and CMU) shows: 60% of tested organizations cannot terminate a misbehaving agent, 63% cannot enforce purpose limits. That's the status quo, not the goal. But the status quo is now being measured — and measurability is the precondition for improvement.
The closing strategy that follows from all this isn't elimination. It's rate reduction across four pillars: grounding mechanisms lower the frequency (RAG, tool use), confidence scoring and source citations raise detectability, maker-checker patterns and human-in-the-loop minimize the impact, transparent communication calibrates user expectations. No silver bullet, but a realistic multi-layered approach.
The DevTools corrections from the beginning of this article took four rounds, but they happened. I was the reality check. The governance infrastructure this article is about is the attempt to build in reality checks for when no one is reading along for four rounds anymore. That's the difference between a tool and a system — and it decides whether agent memory stays a risk or becomes responsible infrastructure.
Originally published on Medium.